Getting Started
Reference Material
The course materials can be accessed on the course website. This is also where you find the textbook to go along with the course
Introduction
Why Program?
- become a creator of technology, don’t just be a consumer of it
- computers want to be helpful (What do you want to do next?)
- a programmer’s job is to intermediate between the hardware and the user
Hardware Overview
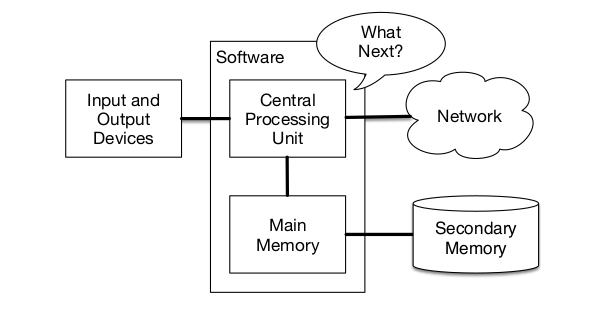
- the CPU is always asking “What next?”
- fetch-execute cycle (between CPU and main memory)
- main memory (deleted when computer is turned off) and secondary memory (remains)
- compiler and interpreter to the translation of the human-readable program code to machine code
Python as a Language
- invented by Guido van Rossum
- named after Monty Python (enjoyable but powerful)
Reserved Words
- you cannot use keywords as variable names
import keyword
print(keyword.kwlist)['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break',
'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for',
'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or',
'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']- if it’s longer than three lines, make a script
- programs can be sequential, conditional (often nested) or repeated (often use iteration variables to make sure that the loop does not run infinitely)
The Building Blocks of a Program
The following are part of every programming language (even machine code):
- input: Data from outside; Read a file, sensor data, keyboard input
- output: The result of the computation displayed on a screen or stored in a file
- sequential execution: Perform statements one after another in the same order in which they are written in the script
- conditional execution: Execute or skip based on a condition
- repeated execution: Perform the same statements repeatedly, usually with some variation
- reuse: Write a set of instructions once and then reuse as needed throughout the program
Different Error Types
Syntax errors
These are the first errors you will make and the easiest to fix. A syntax error means that you have violated the “grammar” rules of Python. Python does its best to point right at the line and character where it noticed it was confused. The only tricky bit of syntax errors is that sometimes the mistake that needs fixing is actually earlier in the program than where Python noticed it was confused. So the line and character that Python indicates in a syntax error may just be a starting point for your investigation.
Logic errors
A logic error is when your program has good syntax but there is a mistake in the order of the statements or perhaps a mistake in how the statements relate to one another. A good example of a logic error might be, “take a drink from your water bottle, put it in your backpack, walk to the library, and then put the top back on the bottle.”
Semantic errors
A semantic error is when your description of the steps to take is syntactically perfect and in the right order, but there is simply a mistake in the program. The program is perfectly correct but it does not do what you intended for it to do. A simple example would be if you were giving a person directions to a restaurant and said, “…when you reach the intersection with the gas station, turn left and go one mile and the restaurant is a red building on your left.” Your friend is very late and calls you to tell you that they are on a farm and walking around behind a barn, with no sign of a restaurant. Then you say “did you turn left or right at the gas station?” and they say, “I followed your directions perfectly, I have them written down, it says turn left and go one mile at the gas station.” Then you say, “I am very sorry, because while my instructions were syntactically correct, they sadly contained a small but undetected semantic error.”.
Debugging
four basic strategies that complement each other (if one does not work, try the next):
- Reading: Examine the code, read it back to yourself and check whether it was what you intended to say
- Running: Experiment by running different versions of the program and try to display the intermediate steps. That sometimes requires some scaffolding
- Ruminating: Think! What kind of error is it? What was the last thing you did before you encountered the error?
- Retreating: At some point, if all the above don’t work, undo the most recent changes until you arrive at a program that you understand and that works as intended.
Variables, Expressions and Statements
Values and Types
print(type("I'm the value"))
print(type("2")
print(type("3.2")<class 'str'> # This is the type
<class 'int'> # This is another type
<class 'float'> # This is another typeVariables
One of the most powerful features of a programming language is the ability to manipulate variables. A variable is a name that refers to a value. The relationship between variable and value is established through an assignment statement - must start with a letter or underscore (only use the underscore if you are writing library code for others though) - always choose mnemonic variable names
hours = 35.0 # this is an assignment statement
rate = 12.50
pay = hours * rate
print(pay)- illegal variable names give a syntax error
Statements
A statement is just a unit of code that the Python interpreter can execute. Scripts are usually a sequence of statements.
Operators and Operands
Operators are defined as special symbols that stand in for computations such as addition, subtraction, multiplication and division. Operands are the values the operator is applied to.
20+32 # "20" and "32" are the operands in this case
hour-1
hour*60+minute
minute/60
5**2
(5+9)*(15-7)Since Python 3.x, the result of a division (of two integers) is a value of the
float type
result = 120/121
print(result)0.9917355371900827If you want a Python 2.x style result, i.e. truncated to the int, then you
need to use //:
result = 120//121
print(result)0Expressions
An expression is a combination of values, variables and operators. But a value all by itself (or a variable - assuming it has a value assigned to it) are also valid expressions. Expressions are evaluated in interactive mode and the results are displayed. In a script, however, expressions by themselves do not produce output.
Order of Operations
The order of evaluation depends on the rules of precedence. Remember PEDMAS:
*P*arentheses *E*xponentiation *M*ultiplication *D*ivision *A*ddition *S*ubstraction
Modulus Operators
This operator works on values of the type int and yields the remainder when
the first operand is divided by the second.
quotient = 7 // 3
print(quotient)
remainder = 7 % 3
print(remainder)2
1String Operations
The +-operator works with strings, it concatenates them, i.e. it joins them
together.
part_one = "Hi, my name is "
part_two = "Linus"
print(part_one + part_two)
print(part_two*2)Hi, my name is Linus
LinusLinusAsking the User for Input
There is a built-in function called input which stops the program and waits
for the user to type something. When the user presses Return, the program
resumes and the function returns whatever was typed as a string. The \n is
called a newline which is a special character that causes a line break (which
is why, in the example below, the user input appears below the prompt)
prompt = "Is this love?\n"
input(prompt)Is this love?
Yes!A little program that prompts the user for a temperature in Celsius and outputs the same temperature in Fahrenheit:
prompt = "Input the degrees Celsius\n"
celsius = input(prompt)
fahrenheit = ( int(celsius) / (5/9) ) + 32
print(fahrenheit)Conditional Execution
Boolean Expressions
Boolean expressions are
expressions that are either True or False.
x = 5
y = 6
print(x == y)
print(type(x == y))False
<class 'bool'>There is also a new range of operators that produce boolean values when evaluated.
x != y # x is not equal to y
x > y# x is greater than y
x < y# x is less than y
x >= y # x is greater than or equal to y
x <= y # x is less than or equal to y
x is y # x is the same as y
x is not y # x is not the same as yLogical Operators
There are three: and (something is True only if both operands are True),
or (True if either of the operands is True) and not (negation of the
expression).
Any nonzero number is interpreted as True
print(17 and True) #True
print(0 and True) #0
print(17 or True) #17
print(0 or True)#True
print(False and 17) #False
print(False and 0) #False
print(False or 17) #17
print(False or 0) #0Conditional Execution
We often need to check certain conditions, and then adapt our program to those conditions.
if x > 0 :
print("x is positive")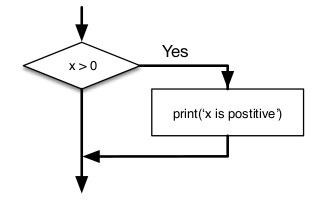
Alternative Execution
A check of the condition leads down exactly one of either of two so-called branches
if x%2 == 0 :
print("x is even")
else :
print("x is odd")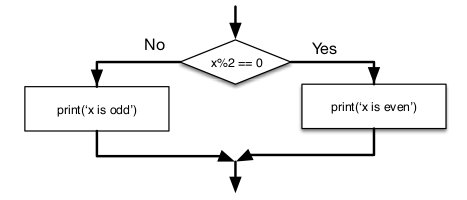
Chained Conditionals
If I want to include more possible branches, I need the elif-statement. Each
condition is checked after the last, if one of them is True, the branch
executes and the statement ends. Even if more conditions are True, only the
first true branch will execute.
if choice == 'a':
print('Bad guess')
elif choice == 'b':
print('Good guess')
elif choice == 'c':
print('Close, but not correct')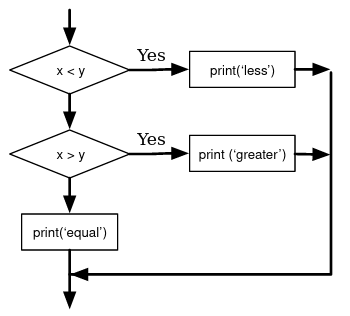
Nested Conditionals
You can nest branches into one another as follows.
if x == y:
print('x and y are equal')
else:
if x < y:
print('x is less than y')
else:
print('x is greater than y')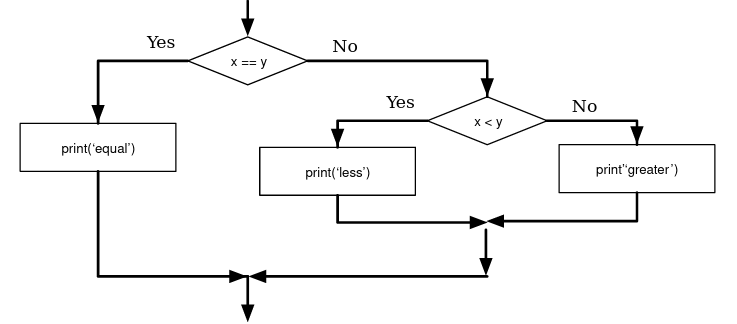
Catching Exceptions using Try and Except
try and except are Python’s built-in insurance policy against errors. Only
if (any) error occurs in the try-block, Python jumps directly to the
except-block. Handling possible errors through with a try-statement is
called catching an error. It gives you the chance to fix the problem, try
again or end the problem gracefully. See the following example for an
illustration of the latter:
inp = input('Enter Fahrenheit Temperature:')
try:
fahr = float(inp)
cel = (fahr - 32.0) * 5.0 / 9.0
print(cel)
except:
print('Please enter a number')Short-circuit Evaluation of Logical Expressions
Consider the following code:
# Example 1
x = 6
y = 2
print("Example 1: " + str(x >= 2 and (x/y) > 2))
#Example 2
x = 1
y = 0
print("Example 2: " + str(x >= 2 and (x/y) > 2))
#Example 3
x = 6
y = 0
print("Example 3: " + str(x >= 2 and (x/y) > 2))Example 1: True
Example 2: False
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
<ipython-input-41-7fc295d23b39> in <module>
12 x = 6
13 y = 0
---> 14 print("Example 3: " + str(x >= 2 and (x/y) > 2))
ZeroDivisionError: division by zeroWe get a an error in the third but not in the second example because Python
noticed that the overall expression in the second case cannot be anything but
False after evaluating the first part, i.e. =x >= 2=. So, it short-circuited
the rest of the evaluation to save its energy.
You can actually use this to guard parts of your evaluation just before the evaluation might cause an error.
x = 6
y = 0
print(str(x >= 2 and y != 0 and (x/y) > 2))In this case, y ! 0= acts as a guard against evaluating (x/y) > 2 when y
is equal to zero.
Functions
Function Calls
At its most basic, a function is a named sequence of statements performing a computation. After having specified the statements, you can call a (built-in) function as such:
print(type(32)) # both print() and type() are functions
max("Hello world") # "w" is the "largest" character
min("Hello world") # the space is the "smallest" character
len("Hello world") # gives the length of a string<class 'int'>
w
11Important Built-in Functions
Type conversion
int converts floating-point numbers and (the right kind of) strings to
integers:
int('32')
int('Hello') # this gives a ValueError
int(3.999999) # int() will not round but truncate
int(-2.3)32
ValueError: invalid literal for int() with base 10: 'Hello'
3
2float converts integers and strings to floating-point numbers:
float(32)
float("3.1415926")32.0
3.1415926str just converts everything to a string:
str(32)
str(3.1415926)"32"
"3.1415926"Math functions
Python ships with a math module that must be imported before it can be used:
import math
print(math) # get some information about the so-called module object<module 'math' (built-in)>The module object contains the functions and variables associated with the module. To call one of those, you need to use the name of the module and the name of the function, separated by a dot (a.k.a. as a period). This is called dot notation.
import math
signal_power = 200 # in microvolts
noise_power = 1 # in microvolts
ratio = signal_power / noise_power
decibels = 10 * math.log10(ratio)
print(str(decibels) + " dB")23.010299956639813 dBAnother example involves getting a variable from the math module and using its
trigonometric functions (sin, cos, tan, etc.):
import math
degrees = 45
# to convert from deg to rad, divide by 360 and multiply by 2π
radians = degrees / 360 * 2 * math.pi
print(math.sin(radians))0.7071067811865475Making Random Numbers
This turns out to be a pretty hard task for most computers as we generally want
them to behave deterministically. When generating random numbers, this is a
problem. But we can make it seem as if the computer is behaving
non-deterministically by using algorithms to generate pseudorandom numbers using
the random- module:
import random
for i in range(10):
x = random.random()
print(x)0.4597169033073607
0.39433343645123353
0.9699872452986879
0.3886217989836309
0.713473451037861
0.05649189351989847
0.8393346778840809
0.37760550337740284
0.03950536181772901
0.7117717795167312The program above produces ten (pseudo-)random numbers between 0.0 up to but
not including 1.0. The randint-function takes the parameters low and
high, and returns an int between low and high (including both):
random.randint(5,10)9To choose a random list from a sequence, use random.choice:
t = [1, 2, 3]
random.choice(t)2Adding New Functions
In order to add functions that we can reuse throughout our program, we need to define them using so-called function definitions:
def print_lyrics():
print("I'm a lumberjack, and I'm okay.")
print("I sleep all night and work all day.")
print(print_lyrics) # shows some information about the newly created variable
print(type(print_lyrics)) # this is function object with the type "function"
print(print_lyrics()) # this is how we call the function<function print_lyrics at 0x7f50bc313290>
<class 'function'>
I'm a lumberjack, and I'm okay.
I sleep all night and work all day.we can reference functions within functions:
def repeat_lyrics():
print_lyrics()
print_lyrics()
print(repeat_lyrics)I'm a lumberjack, and I'm okay.
I sleep all night and work all day.
I'm a lumberjack, and I'm okay.
I sleep all night and work all day.Flow of Execution
Functions can only be called after they are defined. Function definitions, on the other hand, do not alter the execution flow (statement after statement from top to bottom), but you need to remember that statements inside the function are not executed until the function is called.
When reading a program, try to follow the flow of execution rather than trying to read it top to bottom.
Parameters and Arguments
You can pass arguments to functions, e.g. when you call
math.sin(some numeric argument). Inside the functions, the arguments are
assigned to variables called parameters. Consider the following example to
illustrate these concepts:
import math
def print_twice(anything):
print(anything)
print(anything)
print_twice(math.cos(math.pi))-1.0
-1.0Here, it is interesting to note, that the expression math.cos(math.pi) is only
evaluated once (and then printed twice).
Fruitful Functions and Void Functions
In a script some functions are void, i.e. they do not return anything and when
you try to assign them to a value you get a special value called None:
result = print_twice('Bing') # in a script, this does not return anything
print(result) # returns `None`NoneTo return a result from a function, you need to use the return-statement
within the function:
def multiply(a, b):
multiplied = a * b
return multiplied
x = multiply(3, 4)
print(x)12Why Functions?
- Grouping statements in your program into functional units makes it easier to read, understand and debug.
- Functions can make a program smaller by reducing repetitive code.
- Once debugged, well-designed functions can be repurposed within the same program and across other programs.
Iteration
The while statement
This statement first evaluates the condition. If it is false, it exits the
while-statement and continues at the next statment. If the condition is true,
the body is executed and the condition is evaluated again:
n = 5
while n > 0:
print(n)
n = n - 1
print('Blastoff!')5
4
3
2
1
Blastoff!Infinite Loops
If a the condition is always true, the loop will execute until your battery runs
out - unless you make use of break to define a specific exit condition within
the while-statement.
The code below, for instance, asks the user for input (and prints it back to
her) until the user types done:
while True:
line = input('> ')
if line == 'done':
break
print(line)
print('Done!')Finish an Iteration Early
If you want to exit an iteration early (but do not want to exit the entire
loop), you can use the continue-statement. The following code illustrates that
by not printing back lines to the user that start with the #-character.
while True:
line = input('> ')
if line[0] == '#':
continue
if line == 'done':
break
print(line)
print('Done!')Definite Loops Using for
you can loop through a set of things constructing a definitive loop using
the for-statement.
friends = ['Joseph', 'Glenn', 'Sally']
for friend in friends:
print('Happy New Year:', friend)
print('Done!')Happy New Year: Joseph
Happy New Year: Glenn
Happy New Year: Sally
Done!In the code above, friend is the iteration variable, it steps successively
through the items in stored in friends.
Loop Patterns
Counting and Summing Loops
In order to count the number of items in a list, the following for-loop might
be used:
count = 0
for itervar in [3, 41, 12, 9, 74, 15]:
count = count + 1
print('Count: ', count)If you want to sum all the (numerical) items in a list, this code does the job:
total = 0
for itervar in [3, 41, 12, 9, 74, 15]:
total = total + itervar
print('Total: ', total)A variables such as total in the code snippet above is called accumulator.
We won’t need either of the two programs above in practice as we have the
built-in functions len() and sum().
Maximum and Minimum Loops
To emulate what the built-in function max() does, we can start with the
following code:
largest = None
print('Before:', largest)
for itervar in [3, 41, 12, 9, 74, 15]:
if largest is None or itervar > largest :
largest = itervar
print('Loop:', itervar, largest)
print('Largest:', largest)Before: None
Loop: 3 3
Loop: 41 41
Loop: 12 41
Loop: 9 41
Loop: 74 74
Loop: 15 74
Largest: 74None is used in the code above to mark as “empty”. To compute the smallest
number (again, we have built-in min() to do the job in practice) in a list we
can just change the > to a <:
smallest = None
print('Before:', smallest)
for itervar in [3, 41, 12, 9, 74, 15]:
if smallest is None or itervar < smallest:
smallest = itervar
print('Loop:', itervar, smallest)
print('Smallest:', smallest)Debugging by Bisection
When debugging loops always try to check in the middle of the code (if possible). For example, add a print statement in the middle of a loop and check its value. If it is already wrong, you know the bug hides in the first half of your loop body. This way you can cut down the number of lines you have to check quite significantly.
A bit of exercise code that puts lots of the concepts together:
while True:
try:
line = input('> ')
if line == 'done':
break
list.append(int(line))
print("current list items: ")
print(list)
except:
print("Please enter a number")
# compute total
total = 0
for i in list:
total = total + i
# compute count
count = 0
for j in list:
count = count + 1
# compute avg
avg = total / count
print('total: ' + str(total) + "\ncount: " + str(count) + "\naverage: " + str(avg))Data Structures
Strings
A string is a sequence of characters (all unicode in Python 3). Individual characters can be accessed using the bracket operator. Be aware that the index starts at 0 and not at 1.
So, for example, using the len() function to access the last letter of a
string won’t work:
>>> fruit = 'banana'
>>> length = len(fruit)
>>> last = fruit[length]
IndexError: string index out of rangeIt only works if you substract 1 from length:
>>> length = len(fruit)
>>> last = fruit[length-1]
IndexError: string index out of rangeTraversal through a string with a loop
You can traverse a string (stepping through it, looking at and possibly doing
something with each character) with a while loop:
index = 0
while index < len(fruit): # <= would lead to IndexError
letter = fruit[index]
print(letter)
index = index + 1To do the same thing backwards, the while loop above must be adapted as
follows:
index = len(fruit)-1
while index >= 0:
letter = fruit[index]
print(letter)
index = index - 1You can also use a for loop:
for char in fruit:
print(char)String Slices
If you only want to access a segment of a string, a so-called slice, you again use the bracket operator. The following image shows how that is done:
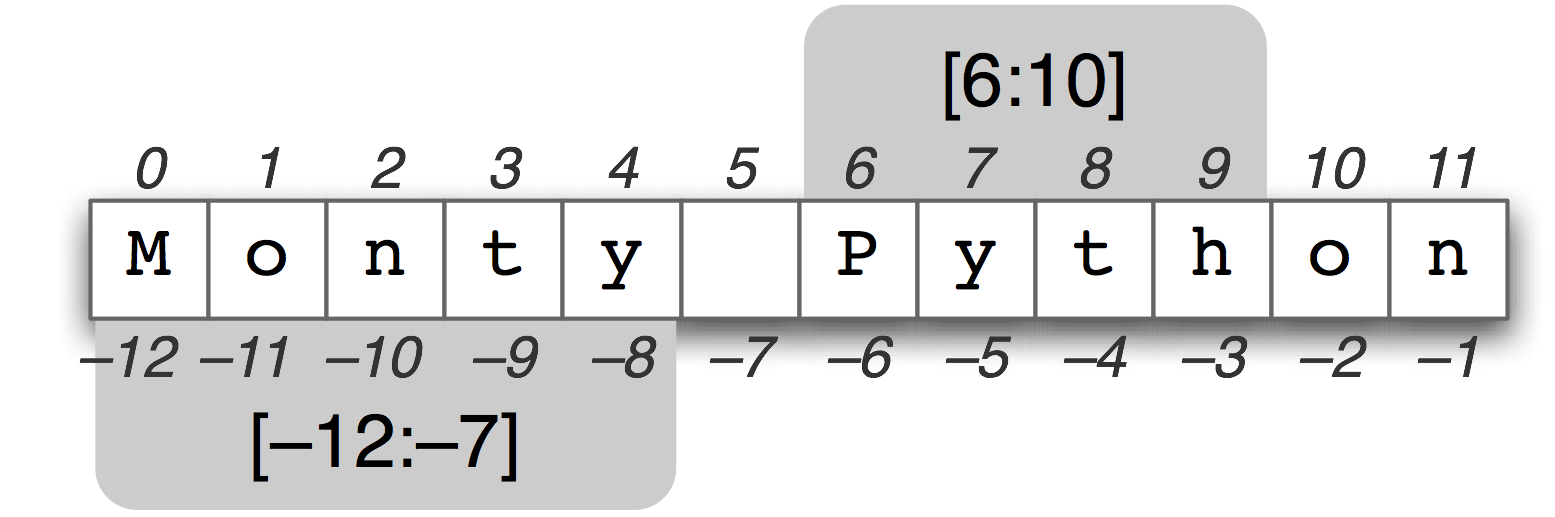
Strings are Immutable
This basically means that you cannot change a single character within the string without reassigning the entire string:
>>> greeting = 'Hello, world!'
>>> greeting[0] = 'J'
TypeError: 'str' object does not support item assignmentWhat you can do is:
>>> greeting = 'Hello, world!'
>>> new_greeting = 'J' + greeting[1:]
>>> print(new_greeting)
Jello, world!Looping and Counting
The following function for instance loops through a string and counts the occurrences of a character given as an argument:
def count_char(word, letter):
count = 0
for l in word:
if l == letter:
count = count + 1
print(count)The in Operator
The in operator just return a boolean value if the first operand is a
substring of the second operand:
>>> "a" in "banana"
TrueString Comparison
Check whether two strings are equal:
if word == 'banana':
print('All right, bananas.')With < and > you can put strings in alphabetical order (beware though that
uppercase letters always come before lowercase ones)
def word_sort(word):
if word < 'banana':
return('Your word, ' + word + ', comes before banana.')
elif word > 'banana':
return('Your word, ' + word + ', comes after banana.')
else:
return('All right, bananas.')
word_sort("Colibri")'Your word, Colibri, comes before banana.'String Methods
You can use the dir function to list the methods (i.e. built-in functions
that are available to any instance of an object):
>>> stuff = 'Hello world'
>>> type(stuff)
<class 'str'>
>>> dir(stuff)
['capitalize', 'casefold', 'center', 'count', 'encode',
'endswith', 'expandtabs', 'find', 'format', 'format_map',
'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit',
'isidentifier', 'islower', 'isnumeric', 'isprintable',
'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower',
'lstrip', 'maketrans', 'partition', 'replace', 'rfind',
'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip',
'split', 'splitlines', 'startswith', 'strip', 'swapcase',
'title', 'translate', 'upper', 'zfill']
>>> help(str.capitalize)
Help on method_descriptor:
capitalize(...)
S.capitalize() -> str
Return a capitalized version of S, i.e. make the first character
have upper case and the rest lower case.To call (the correct therm is invoking) a method we append its name (delimited by space) to the object that we want to apply it to. There is a whole range of cool string methods, but the following examples only focus on some.
.upper() and .lower() make entire strings upper or lowercase.
>>> word = 'banana'
>>> new_word = word.upper()
>>> print(new_word)
BANANA.find() can find substrings within strings. It can also take a start index as
a second argument:
>>> word.find('na')
2
>>> word.find('na', 3)
4.strip() removes all spaces, tabs or spaces from a string. .startswith()
returns a boolean value if the string starts with the argument you give to it.
If you want to make a case-insensitive search, you can chain .lower() and
.startswith() together as such:
>>> line = "My name is Linus"
>>> line.lower().startswith('my')
TrueParsing Strings
You can use .find() to extract only the substrings of interest (like the hosts
in an e-mail header):
>>> data = 'From stephen.marquard@uct.ac.za Sat Jan 5 09:14:16 2008'
>>> atpos = data.find('@')
>>> print(atpos)
21
>>> sppos = data.find(' ',atpos)
>>> print(sppos)
31
>>> host = data[atpos+1:sppos]
>>> print(host)
uct.ac.za
>>>Format Operator
With the format operator, %, you are able to construct strings and
dynamically replace values within it with data stored in other variables. An
example:
>>> camels = 42
>>> 'I own %d camels' % camels
'I own 42 camels'You can use different formatting like %d for integers, %g for decimals and
%s for normal strings:
>>> 'In %d years I have spotted %g %s.' % (3, 0.1, 'camels')
'In 3 years I have spotted 0.1 camels.'Files
Opening Files
When opening files, you are accessing (reading or writing) secondary memory. In
Python, you use the open() function to do that. If it successfully opens a
file, it returns the user a file hadle that can be used to access the data in
the file:
>>> fhand = open('mbox.txt')
>>> print(fhand)
<_io.TextIOWrapper name='mbox.txt' mode='r' encoding='UTF-8'>All the mentioned files should be available here.
Reading Files
As mentioned already, the file handle does not really contain the data, it is
just reference to it. However, you can easily create a for loop to count the
lines of a given text file.
fhand = open('mbox-short.txt')
count = 0
for line in fhand:
count = count + 1
print('Line Count:', count)Line Count: 1910The advantage of the method above is that it does not require much memory, as
each line is read, counted and then discarded before the next one is put into
memory. If we know the file is small enough to be handled by (primary) memory,
we can use the .read() method on the file handle.
>>> fhand = open('mbox-short.txt')
>>> inp = fhand.read()
>>> print(len(inp))
94626
>>> print(inp[:20])
From stephen.marquarSearching Through a File
To print only the lines that start with “From:”, you can use the following code combining the patterns for reading a file with the string methods from the last section:
fhand = open('mbox-short.txt')
count = 0
for line in fhand:
if line.startswith('From:'):
print(line)From: stephen.marquard@uct.ac.za
From: louis@media.berkeley.edu
From: zqian@umich.edu
From: rjlowe@iupui.edu
...Why is there a new line between the lines of the output? Because the
newline-character from the print() function is combined with the invisible
newline-character from the file. You can use the .rstrip() method to
ameliorate this problem:
fhand = open('mbox-short.txt')
for line in fhand:
line = line.rstrip()
if line.startswith('From:'):
print(line)From: stephen.marquard@uct.ac.za
From: louis@media.berkeley.edu
From: zqian@umich.edu
From: rjlowe@iupui.edu
From: zqian@umich.edu
From: rjlowe@iupui.edu
From: cwen@iupui.edu
...Next, you can structure the for loop using continue in order to skip
“uninteresting” lines:
fhand = open('mbox-short.txt')
for line in fhand:
line = line.rstrip()
# Skip 'uninteresting lines'
if not line.startswith('From:'):
continue
# Process our 'interesting' line
print(line)You can also use the .find() string method which returns the index of the
searched substring or -1 if the substring was not found in order to show lines
which contain “@uct.ac.za”:
fhand = open('mbox-short.txt')
for line in fhand:
line = line.rstrip()
# contracted version of the if-function
if line.find('@uct.ac.za') == -1: continue
print(line)From stephen.marquard@uct.ac.za Sat Jan 5 09:14:16 2008
X-Authentication-Warning: set sender to stephen.marquard@uct.ac.za using -f
From: stephen.marquard@uct.ac.za
Author: stephen.marquard@uct.ac.za
From david.horwitz@uct.ac.za Fri Jan 4 07:02:32 2008
X-Authentication-Warning: set sender to david.horwitz@uct.ac.za using -f
From: david.horwitz@uct.ac.za
Author: david.horwitz@uct.ac.za
...Letting the User Choose the File Name
The following code asks the user to input the file name:
fname = input('Enter the file name: ')
fhand = open(fname)
count = 0
for line in fhand:
if line.startswith('Subject:'):
count = count + 1
print('There were', count, 'subject lines in', fname)Enter the file name: mbox.txt
There were 1797 subject lines in mbox.txtObviously, the code above does not know how to handle unexpected or faulty user
input gracefully. To solve this, remember what try and expect can do for
you.
Using try, except and open
We can use the aforementioned error handling structures to fix the flaw in the program:
fname = input('Enter the file name: ')
try:
fhand = open(fname)
except:
print('File cannot be opened:', fname)
exit()
count = 0
for line in fhand:
if line.startswith('Subject:'):
count = count + 1
print('There were', count, 'subject lines in', fname)Enter the file name: mbox.txt
There were 1797 subject lines in mbox.txtEnter the file name: na na boo boo
File cannot be opened: na na boo booWriting Files
If you want to write a file, i.e. change it using Python, you have to open it with “w” as a second parameter:
>>> fout = open.('output.txt', 'w')
>>> print(fout)
<_io.TextIOWrapper name='output.txt' mode='w' encoding='UTF-8'>You have to be careful though as opening a file in write mode clears out all the
data stored in the file currently. The .write() method of the file handle
object puts data into the file and returns the number of characters written:
>>> line1 = "This is cool,\n"
>>> fout.write(line1)
14
# you always need to close the file if we are writing files
>>> fout.close
<function TextIOWrapper.close()>In IPython Notebooks you can use the `writefile output.txt test test2
Print the content of `output.txt` back:
```python
with open('output.txt', 'r') as f:
print(f.read())
test
test2Dealing with the Invisible
Errors through whitespace can sometimes be hard to debug because, spaces, tabs and newlines are normally invisible:
>>> s = '1 2\t 3\n 4'
>>> print(s)
1 2 3
4The built-in repr() function can help by returning string representations of
the object
>>> print(repr(s))
'1 2\t 3\n 4'Exercises
The exercises in this chapter are the first ones interesting enough to be worked through in detail:
Exercise 1: Write a program to read through a file and print the contents of the file (line by line) all in upper case. Executing the program will look as follows:
python shout.py
Enter a file name: mbox-short.txt
FROM STEPHEN.MARQUARD@UCT.AC.ZA SAT JAN 5 09:14:16 2008
RETURN-PATH: <POSTMASTER@COLLAB.SAKAIPROJECT.ORG>
RECEIVED: FROM MURDER (MAIL.UMICH.EDU [141.211.14.90])
BY FRANKENSTEIN.MAIL.UMICH.EDU (CYRUS V2.3.8) WITH LMTPA;
SAT, 05 JAN 2008 09:14:16 -0500Solution:
fname = input('Enter a file name: ')
try:
fhand = open(fname)
for line in fhand:
line = line.rstrip().upper()
print(line)
except FileNotFoundError:
print('File cannot be openend: ', fname)Exercise 2: Write a program to prompt for a file name, and then read through the file and look for lines of the form:
X-DSPAM-Confidence: 0.8475When you encounter a line that starts with “X-DSPAM-Confidence:” pull apart the line to extract the floating-point number on the line. Count these lines and then compute the total of the spam confidence values from these lines. When you reach the end of the file, print out the average spam confidence.
Solution:
fname = input('Enter a file name: ')
confs = []
try:
fhand = open(fname)
for line in fhand:
if line.startswith('X-DSPAM-Confidence:'):
float_start = line.find(':') + 2
confs.append(float(line[float_start:]))
total = len(confs)
avg = sum(confs) / total
print('total: ', total, '\naverage: ', avg)
except FileNotFoundError:
print('File cannot be openend: ', fname)Enter a file name: mbox-short.txt
total: 27
average: 0.7507185185185187
Enter a file name: mbox.txt
total: 1797
average: 0.8941280467445736Exercise 3: Sometimes when programmers get bored or want to have a bit of fun, they add a harmless Easter Egg to their program. Modify the program that prompts the user for the file name so that it prints a funny message when the user types in the exact file name “na na boo boo”. The program should behave normally for all other files which exist and don’t exist. Here is a sample execution of the program:
python egg.py
Enter the file name: na na boo boo
NA NA BOO BOO TO YOU - You have been punk'd!Solution:
fname = input('Enter a file name: ')
if fname == "na na boo boo":
print("NA NA BOO BOO TO YOU - You have been punk'd")
exit()
confs = []
try:
fhand = open(fname)
for line in fhand:
if line.startswith('X-DSPAM-Confidence:'):
float_start = line.find(':') + 2
confs.append(float(line[float_start:]))
total = len(confs)
avg = sum(confs) / total
print('total: ', total, '\naverage: ', avg)
except FileNotFoundError:
print('File cannot be openend: ', fname)Lists
Similar to strings, lists are also sequences of values. While in a string the values are characters, they can be of any type in a list. The values of lists are called elements or items. The elements of a list don’t all have to be the same type; they can even be lists themselves (i.e. nested lists):
['spam', 2.0, 5, [10, 20]]Lists are Mutable
Unlike strings, lists are mutable. Using the known bracket operator, we can access and change the elements of a list:
>>> cheeses = ['Cheddar', 'Edam', 'Gouda']
>>> numbers = [17, 123]
>>> numbers[1] = 5
>>> print(numbers)
[17, 5]
>>> numbers[-1] = 3
>>> print(numbers)
[17, 3]The in operator also works on lists:
>>> 'Edam' in cheeses
TrueTraversing a List
Most commonly, you will use a for loop:
for cheese in cheeses:
print(cheese)This, however, only works for reading and not for writing or updating the
elements of the list; for that, you need the indices. For example you can
combine the range (returns a list of indices from 0 to n - 1) and len (n,
i.e. number of items in list) functions:
for i in range(len(numbers)):
numbers[i] = numbers[i] * 2Although a list can contain another list, the nested list will still count as a single element.
List Operations
You can concatenate lists using the + operator:
>>> a = [1, 2, 3]
>>> b = [4, 5, 6]
>>> c = a + b
>>> print(c)
[1, 2, 3, 4, 5, 6]The * operator repeats the list n times
>>> [0] * 4
[0, 0, 0, 0]
>>> [1, 2, 3] * 3
[1, 2, 3, 1, 2, 3, 1, 2, 3]List Slices
You can use the slice operator on lists:
>>> t = ['a', 'b', 'c', 'd', 'e', 'f']
>>> t[1:3]
['b', 'c']
>>> t[:4]
['a', 'b', 'c', 'd']
>>> t[3:]
['d', 'e', 'f']Omitting the first index means starting at the beginning and omitting the second means going until the end:
>>> t[:]
['a', 'b', 'c', 'd', 'e', 'f']Due to the fact that lists are mutable, you can update multiple elements at a time. Sometimes its better to store the changed list in a new variable such that a copy of the unchanged list is kept:
>>> t = ['a', 'b', 'c', 'd', 'e', 'f']
>>> t_new = ['a', 'b', 'c', 'd', 'e', 'f']
>>> t_new[1:3] = ['x', 'y']
>>> print(t_new)
['a', 'x', 'y', 'd', 'e', 'f']List Methods
One of the most important methods for list-objects is the .append() method
which adds a new element to the end of a list.
>>> t = ['a', 'b', 'c']
>>> t.append('d')
>>> print(t)
['a', 'b', 'c', 'd'].extend() takes another list as an argument and appends all of its items to
the list-object that it operates on:
>>> t1 = ['a', 'b', 'c']
>>> t2 = ['d', 'e']
>>> t1.extend(t2)
>>> print(t1)
['a', 'b', 'c', 'd', 'e']t2 remains unmodified in the example above.
Most list methods are void, i.e. they change the list object that they operate
on and return None. So assigning them to variables won’t bring the desired
result. For an example, see the .sort() method that sorts a list from high to
low:
>>> t = ['d', 'c', 'e', 'b', 'a']
>>> t.sort()
>>> print(t.sort())
None
>>> print(t)
['a', 'b', 'c', 'd', 'e']Deleting Elements
You can delete elements from lists in several different ways. If you know the
index, use the .pop() method which, if no index is given, it just deletes and
returns the last element of a list:
>>> t = ['a', 'b', 'c']
>>> x = t.pop(1)
>>> print(t)
['a', 'c']
>>> print(x)
b
>>> t.pop()
'c'If there is no need to return anything, you can use the del operator which
uses the following syntax:
>>> t = ['a', 'b', 'c']
>>> del t[1]
>>> print(t)
['a', 'c']If you already know what to remove, but don’t know where it is in the list, use
the .remove() method:
>>> t = ['a', 'b', 'c']
>>> print(t.remove('b'))
None
>>> print(t)
['a', 'c']
>>> t_new = ['a', 'b', 'c', 'd', 'e', 'f']
>>> del t[1:5]
>>> print(t_new)
['a', 'f']Lists and Functions
There are a number of useful built-in functions that work on lists. max() and
len() work with lists that contain elements of all (comparable) types. The
sum() function only works with lists containing numbers.
>>> nums = [3, 41, 12, 9, 74, 15]
>>> print(len(nums))
6
>>> print(max(nums))
74
>>> print(min(nums))
3
>>> print(sum(nums))
154
>>> print(sum(nums)/len(nums))
25Using these, we can rewrite the following program that takes user input and computes the average from this:
total = 0
count = 0
while (True):
inp = input('Enter a number: ')
if inp == 'done': break
value = float(inp)
total = total + value
count = count + 1
average = total / count
print('Average:', average)to this:
numlist = list()
while (True):
inp = input('Enter a number: ')
if inp == 'done': break
value = float(inp)
numlist.append(value)
average = sum(numlist) / len(numlist)
print('Average:', average)Lists and Strings
Converting a string (sequence of characters) to a list (sequence of values) is
easy using the built-in list function:
>>> s = 'spam'
>>> t = list(s)
>>> print(t)
['s', 'p', 'a', 'm']If you need to break a string into multiple words, use the .split() method:
>>> s = 'pining for the fjords'
>>> t = s.split()
>>> print(t)
['pining', 'for', 'the', 'fjords']
>>> print(t[2])
theIf you want the .split() method to split not at spaces, but somewhere else,
you have to provide the desired delimiter as an argument:
>>> s = 'spam-spam-spam'
>>> delimiter = '-'
>>> s.split(delimiter)
['spam', 'spam', 'spam']You can think of the .join() method as the inverse of the .split() method.
It takes a list of strings as an argument and concatenates them. It needs to be
invoked on the delimiter:
>>> t = ['pining', 'for', 'the', 'fjords']
>>> delimiter = ' '
>>> delimiter.join(t)
'pining for the fjords'Parsing Lines Using .split()
The .split() method is very helpful if you want to do something other than
printing whole lines when reading a file. You can find the “interesting” lines
and then parse the line to find the interesting part of the line. The
following code prints the day of the week from our mbox-file from earlier:
fhand = open('mbox-short.txt')
for line in fhand:
line = line.rstrip()
if not line.startswith('From '): continue
words = line.split()
print(words[2])Sat
Fri
Fri
Fri
...Objects and Values
When assigning a and b to the same string, Python only creates one string
object and both a and b refer to it:
>>> a = 'banana'
>>> b = 'banana'
>>> a is b
TrueDoing the same with lists, however, creates two distinct objects, which are equivalent (have the same value) but not identical (because they are not the same object):
>>> a = [1, 2, 3]
>>> b = [1, 2, 3]
>>> a is b
FalseAliasing
However, if a refers to a (list) object, and you assign b = a, then both
variables reference the same object:
>>> a = [1, 2, 3]
>>> b = a
>>> b is a
TrueThe association of a variable with an object is called a reference. If an object has more than one reference, the object is aliased. If the aliased object is mutable (e.g. a list), the changes made using one alias will affect the other:
>>> b[0] = 17
>>> print(a)
[17, 2, 3]While sometimes useful, you should avoid aliasing mutable objects. Aliasing immutable object is not such a big deal as it hardly ever makes a difference.
List Arguments
The following function delete_head removes the first element from a list:
def delete_head(t):
del t[0]This is how it is used:
>>> letters = ['a', 'b', 'c']
>>> delete_head(letters)
>>> print(letters)
['b', 'c']t and letters are aliases for the same object. There is an important
distinction between operations modifying a list and those creating a list.
For instance, the .append() method modifies a list while the + operator
creates a new one:
>>> t1 = [1, 2]
>>> t2 = t1.append(3)
>>> print(t1)
[1, 2, 3]
>>> print(t2)
None
>>> t3 = t1 + [3]
>>> print(t3)
[1, 2, 3]
>>> t2 is t3
FalseConsider the following function definition:
def bad_delete_head(t):
t = t[1:] # WRONGThis function leaves the original list unmodified, i.e. the list that was passed as an argument. Alternatively, you can write a function that creates and returns a new list:
def tail(t):
return t[1:]This function leaves the original list unmodified:
>>> letters = ['a', 'b', 'c']
>>> rest = tail(letters)
>>> print(rest)
['b', 'c']Exercise 8.1:
Write a function called chop that takes a list and modifies it, removing the first and last elements, and returns None. Then write a function called middle that takes a list and returns a new list that contains all but the first and last elements.
Solution
t1 = ["a", "b", "c"]
t2 = ["a", "b", "c"]
def chop(t):
del t[0]
del t[-1]
def middle(t):
return t[1:-1]
print(chop(t1))
print(t1)
print(middle(t2))None
['b']
['b']Pitfalls
List Methods Returning None
Most list methods return None, so the following does not make much sense:
t = t.sort() # WRONGPick an Idiom (and Stick with it)
Pick one way to do things and stick to it. With lists there are often too many
ways to do the same thing (e.g. =pop=, remove, del and even slice
assignments can be used to remove an element from a list). To add an element,
you can use the append method or the + operator. However, only the following
way is correct if you want to modify an existing list by adding the value of x
to it:
t.append(x)
t = t + [x]and these are wrong:
t.append([x]) # Adds nested list containing variable to list
t = t.append(x) # t is now None
t + [x] # does not modify the list
t = t + x # if x is not a list, this returns a TypeErrorMake Copies
If you want to use a method like sort, but you want to keep the original
(unsorted) list, you should make a copy:
orig = t[:]
t.sort()Lists, split and Files
Consider the following code to parse the weekdays from a text file and the error message we get when running it:
fhand = open('mbox-short.txt')
for line in fhand:
words = line.split()
if words[0] != 'From' : continue
print(words[2])Sat
Traceback (most recent call last):
File "search8.py", line 5, in <module>
if words[0] != 'From' : continue
IndexError: list index out of rangeLet’s add some print statements for the purposes of debugging:
for line in fhand:
words = line.split()
print('Debug:', words)
if words[0] != 'From' : continue
print(words[2])Debug: ['X-DSPAM-Confidence:', '0.8475']
Debug: ['X-DSPAM-Probability:', '0.0000']
Debug: []
Traceback (most recent call last):
File "search9.py", line 6, in <module>
if words[0] != 'From' : continue
IndexError: list index out of rangethe list words seems to be empty and a look into the text file betrays that
there is an empty line when the code throws us an error. The index 0 is out of
range because the list we constructed is empty. We can remedy this using a
guardian condition:
fhand = open('mbox-short.txt')
count = 0
for line in fhand:
words = line.split()
# print('Debug:', words)
if len(words) == 0 : continue
if words[0] != 'From' : continue
print(words[2])Exercise 8.2
Figure out which line of the above program is still not properly guarded. See if you can construct a text file which causes the program to fail and then modify the program so that the line is properly guarded and test it to make sure it handles your new text file.
Solution
There is the possibility that a line just has the word “From” in it. Then our
little program throws us another IndexError because words[2] will be out of
range in a list that has a length of 1. In order to guard against that, the
first if condition should be modified as follows:
...
if len(words) < 2 : continue
...Exercise 8.3
Rewrite the guardian code in the above example without two if statements. Instead, use a compound logical expression using the or logical operator with a single if statement.
Solution
fhand = open('mbox-short-alt.txt')
count = 0
for line in fhand:
words = line.split()
# print('Debug:', words)
if len(words) < 2 or words[0] != 'From' : continue
print(words[2])Exercise 8.4
Write a program to open the file romeo.txt and read it line by line. For each line, split the line into a list of words using the split function. For each word, check to see if the word is already in a list. If the word is not in the list, add it to the list. When the program completes, sort and print the resulting words in alphabetical order.
Solution
wordlist = []
fhand = open('romeo.txt')
for line in fhand:
words = line.split()
for word in words:
if word in wordlist : continue
wordlist.append(word)
sorted_words = sorted(wordlist)
print(sorted_words)Exercise 8.5
Write a program to read through the mail box data and when you find line that
starts with “From”, you will split the line into words using the split
function. We are interested in who sent the message, which is the second word on
the From line. You will parse the From line and print out the second word for
each From line, then you will also count the number of From (not From:) lines
and print out a count at the end.
Solution
fhand = open('mbox-short.txt')
count = 0
for line in fhand:
words = line.split()
if len(words) < 2 or words[0] != 'From' : continue
count += 1
# print("Debug:", words, count)
print(words[1])
print("There were", count, "lines in the file with From as the first word")Exercise 8.6
Rewrite the program that prompts the user for a list of numbers and prints out
the maximum and minimum of the numbers at the end when the user enters “done”.
Write the program to store the numbers the user enters in a list and use the
max() and min() functions to compute the maximum and minimum numbers after
the loop completes.
Solution
num_list = []
while True:
try:
num = input("Enter a number: ")
if num == "done" : break
num = float(num)
num_list.append(num)
except:
print("Please enter a number")
print("Maximum:", max(num_list), "\nMinimum:", min(num_list))Dictionaries
A dictionary is similar to a list, but less restrictive. While in lists, the indeces have to be integers, they can be of (almost) any type in dictionaries. Fundamentally, a dictionary maps keys (our indeces) to values. This association is called a key-value pair.
>>> eng2sp = dict()
>>> print(eng2sp)
{}The curly brackets, {}, denote an empty dictionary. If you want to add items
to the dictionary, use the following syntax:
>>> eng2sp['one'] = 'uno'
>>> print(eng2sp)
{'one', 'uno'}The output format is equivalent to an input format, i.e. you can create a new dictionary with three items as such:
>>> eng2sp = {'one': 'uno', 'two': 'dos', 'three': 'tres'}
>>> print(eng2sp)
{'one': 'uno', 'three': 'tres', 'two': 'dos'}Interestingly, the order of the key-value pairs changed. This is to be expected. It is not a problem because we need the keys to look up values anyways. If the key does not exist we get a KeyError.
>>> print(eng2sp['two'])
'dos'
>>> print(eng2sp['four'])
KeyError: 'four'The len() function also works with dictionaries; it simply returns the number
of key-value pairs.
>>> len(eng2sp)
3The in operator works on dictionaries, too. It only tells you whether
something appears as a key in the dictionary (if it just appears as a value,
this is not good enough):
>>> 'one' in eng2sp
True
>>> 'uno' in eng2sp
FalseIf you want to know whether something exists as a value in a dictionary, you can use the following workaround:
>>> vals = list(eng2sp.values())
>>> 'uno' in vals
TrueExercise 9.1
Write a program that reads the words in
words.txt and stores them as keys in a
dictionary. It doesn’t matter what the values are. Then you can use the in
operator as a fast way to check whether a string is in the dictionary.
Solution
word_dict = dict()
fhand = open('words.txt')
word_id = 1
for line in fhand:
words = line.split()
for word in words:
word_id += 1
if word in word_dict : continue
word_dict[word] = word_id
print(word_dict)Dictionaries as Sets of Counters
With dictionaries, we can now implement a more elegant solution to the problem of counting the occurrence of characters within any given string:
word = "brontosaurus"
d = dict()
for c in word:
if c not in d:
d[c] = 1
else:
d[c] = d[c] + 1
print(d){'a': 1, 'b': 1, 'o': 2, 'n': 1, 's': 2, 'r': 2, 'u': 2, 't': 1}Effectively, this computes a histogram, which is the statistical term for a set of counters (or frequencies for that matter).
The .get() method takes both a key and a default value. If the key appears in
the dictionary, .get() returns the corresponding values; otherwise it returns
the specified default value:
>>> counts = { 'chuck' : 1 , 'annie' : 42, 'jan': 100}
>>> print(counts.get('jan', 0))
100
>>> print(counts.get('tim', 0))
0Utilising the .get() method of dictionaries allows us to write the code above
more succinctly:
word = 'brontosaurus'
d = dict()
for c in word:
d[c] = d.get(c,0) + 1
print(d)Dictionaries and Files
You can use dictionaries to count the occurrence of words in a text file (For now, this uses a version of the romeo.txt file that has now punctuation):
fname = input('Enter the file name: ')
try:
fhand = open(fname)
except:
print('File cannot be opened:', fname)
exit()
counts = dict()
for line in fhand:
words = line.split()
for word in words:
if word not in counts:
counts[word] = 1
else:
# counts[word] = counts[word] + 1
counts[word] += 1
print(counts)Enter the file name: romeo.txt
{'and': 3, 'envious': 1, 'already': 1, 'fair': 1,
'is': 3, 'through': 1, 'pale': 1, 'yonder': 1,
'what': 1, 'sun': 2, 'Who': 1, 'But': 1, 'moon': 1,
'window': 1, 'sick': 1, 'east': 1, 'breaks': 1,
'grief': 1, 'with': 1, 'light': 1, 'It': 1, 'Arise': 1,
'kill': 1, 'the': 3, 'soft': 1, 'Juliet': 1}Looping Through Dictionaries
As it is not very convenient to look through the output above, let’s write a
for loop that traverses the dictionary and prints the key-value pairs.
counts = { 'chuck' : 1 , 'annie' : 42, 'jan': 100}
for key in counts:
print(key, counts[key])jan 100
chuck 1
annie 42However, as dictionaries are unordered (since Python 3.6+, they are insertion ordered), you need to find a way to order the output using a list. This is easy:
counts = { 'chuck' : 1 , 'annie' : 42, 'jan': 100}
# Make a list of the values that we can sort
lst = list(counts.values())
lst.sort()
# Invert the dictionary (use .iteritems() for Python 2.7)
counts_inv = dict((v,k) for k, v in counts.items())
for value in lst:
print(value, counts_inv[value])1 chuck
42 annie
100 janAdvanced Text Parsing
In order to deal with the punctuation in the real
romeo.txt file, you need string methods.
They also allow you to not count “Who” and “who” as different words but as the
same. Most importantly, you need the .translate() method. The documentation
for that method reads as follows:
line.translate(str.maketrans(fromstr, tostr, deletestr))Replace the characters in
fromstrwith the character in the same position intostrand delete all characters that are indeletestr. Thefromstrandtostrcan be empty strings and thedeletestrparameter can be omitted.
Additionally, Python already has a built-in concept of punctuation:
>>> import string
>>> string.punctuation
'!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'Hence, you can adapt the code from earlier:
import string
fname = input('Enter the file name: ')
try:
fhand = open(fname)
except:
print('File cannot be opened:', fname)
exit()
counts = dict()
for line in fhand:
line = line.rstrip()
line = line.translate(line.maketrans('', '', string.punctuation))
line = line.lower()
words = line.split()
for word in words:
if word not in counts:
counts[word] = 1
else:
counts[word] += 1
print(counts)Now, analysing the file romeo-full.txt with this code provides the following output:
Enter the file name: romeo-full.txt
{'swearst': 1, 'all': 6, 'afeard': 1, 'leave': 2, 'these': 2,
'kinsmen': 2, 'what': 11, 'thinkst': 1, 'love': 24, 'cloak': 1,
a': 24, 'orchard': 2, 'light': 5, 'lovers': 2, 'romeo': 40,
'maiden': 1, 'whiteupturned': 1, 'juliet': 32, 'gentleman': 1,
'it': 22, 'leans': 1, 'canst': 1, 'having': 1, ...}Debugging Dictionaries
Scale Down the Input For instance, modify your program such that it only
reads the first n lines. If there is an error, reduce n to the smallest
value that manifests and error.
Check Summaries and Types Check the total number of items in a dictionary (and their types) or the total of a list of numbers (and their types).
Write Self-Checks Try to detect completely illogical outputs by checking for errors automatically. For example, check that the average of a list cannot be larger than the largest element of a list or less than the smallest.
Pretty Print Good formatting of your output can make it easier to spot an error. The time you spend building good scaffolding reduces the time you spend debugging.
Exercise 9.2
Write a program that categorizes each mail message by which day of the week the commit was done. To do this look for lines that start with “From”, then look for the third word and keep a running count of each of the days of the week. At the end of the program print out the contents of your dictionary (order does not matter).
Solution
fname = input('Enter the file name: ')
try:
fhand = open(fname)
except:
print('File cannot be opened:', fname)
exit()
weekday_count = dict()
for line in fhand:
words = line.split()
for word in words:
if word != "From" or len(words[2]) != 3 : continue
weekday_count[words[2]] = weekday_count.get(words[2],0) + 1
print(weekday_count)Enter the file name: mbox.txt
{'Sat': 61, 'Fri': 315, 'Thu': 392, 'Wed': 292, 'Tue': 372, 'Mon': 299, 'Sun': 66}Exercise 9.3
Write a program to read through a mail log, build a histogram using a dictionary to count how many messages have come from each email address, and print the dictionary.
Solution
fname = input('Enter the file name: ')
try:
fhand = open(fname)
except:
print('File cannot be opened:', fname)
exit()
email_count = dict()
for line in fhand:
if not line.startswith('From ') : continue
words = line.split()
for word in words:
if '@' in word:
email_count[word] = email_count.get(word,0) + 1
print(email_count)Enter the file name: mbox-short.txt
{'stephen.marquard@uct.ac.za': 2, 'louis@media.berkeley.edu': 3, 'zqian@umich.edu': 4, 'rjlowe@iupui.edu'
: 2, 'cwen@iupui.edu': 5, 'gsilver@umich.edu': 3, 'wagnermr@iupui.edu': 1, 'antranig@caret.cam.ac.uk': 1,
'gopal.ramasammycook@gmail.com': 1, 'david.horwitz@uct.ac.za': 4, 'ray@media.berkeley.edu': 1}Exercise 9.4
Add code to the above program to figure out who has the most messages in the file. After all the data has been read and the dictionary has been created, look through the dictionary using a maximum loop (see Chapter 5: Maximum and minimum loops) to find who has the most messages and print how many messages the person has.
Solution
fname = input('Enter the file name: ')
try:
fhand = open(fname)
except:
print('File cannot be opened:', fname)
exit()
# Same as above
email_count = dict()
for line in fhand:
if not line.startswith('From ') : continue
words = line.split()
for word in words:
if '@' in word:
email_count[word] = email_count.get(word,0) + 1
# Find largest using max-loop
largest = None
for i in email_count.values():
if largest is None or i > largest:
largest = i
# Make list of the keys and of the values
lst_key = list(email_count.keys())
lst_val = list(email_count.values())
# Denote index of largest value
ind_largest = lst_val.index(largest)
# Print
print(lst_key[ind_largest], largest)Enter a file name: mbox.txt
zqian@umich.edu 195Exercise 9.5
This program records the domain name (instead of the address) where the message was sent from instead of who the mail came from (i.e., the whole email address). At the end of the program, print out the contents of your dictionary.
Solution
fname = input('Enter the file name: ')
try:
fhand = open(fname)
except:
print('File cannot be opened:', fname)
exit()
host_count = dict()
for line in fhand:
if not line.startswith('From ') : continue
words = line.split()
for word in words:
if not "@" in word : continue
email = word.split("@")
host = email[1]
host_count[host] = host_count.get(host,0) + 1
print(host_count)Tuples
Immutability of Tuples
Again, when dealing with tuples, you are dealing with a sequence of values; they can be of any type and are indexed by integers. In contrasts to lists, however, tuples are immutable, i.e. individual elements cannot be changed without changing the whole. Also, they are comparable and hashable such that you can sort lists of tuples and use them as key values in dictionaries. tuples are assigned in either of two ways:
>>> t = ('a', 'b', 'c')
>>> t = ('a',) # note the final comma when defining one-element tuples
>>> t = tuple('lupins') # use the constructor
>>> print(t)
('l', 'u', 'p', 'i', 'n', 's')Again, the slice operator can be used:
>>> print(t[1:3])
('u', 'p')But due to the immutability of the tuple, trying to modify one of its elements throws a TypeError:
>>> t[0] = 'A'
TypeError: object doesn't support item assignmentYou can replace the entire tuple though:
t = ('L',) + t[1:]
print(t)
('L', 'u', 'p', 'i', 'n', 's')Comparing Tuples
The comparison operators work with two tuples (or two lists, two strings etc.). To begin with, the first elements are compared. If they are equal, it compares the next element and so on. Elements after the one that differs between the two sequences are not considered, even if they are really large:
>>> (0, 1, 2) < (0, 3, 4)
True
>>> (0, 1, 2000000) < (0, 3, 4)
TrueThe sort() function for lists (of tuples) works in a similar way. It first
sorts by first element and if there is a tie, it sorts by second element and so
on.
There is a design pattern called DSU that makes use of this feature:
Decorate a sequence by building a list of tuples with one or more sort keys preceding the elements from the sequence,
Sort the list of tuples using the Python built-in sort, and
Undecorate by extracting the sorted elements of the sequence.
As an example, consider the following code that takes a list of words and sorts them from longest to shortest:
txt = 'but soft what light in yonder window breaks'
words = txt.split()
# build a list of tuples
t = list()
for word in words:
t.append((len(word), word))
# sort that list
t.sort(reverse=True)
# output only the words in the correct order
res = list()
for length, word in t:
res.append(word)
print(res)Tuple Assignment
A cool syntactic feature of Python is that you can have a tuple on the left side of an assignment statement:
>>> m = [ 'have', 'fun' ]
>>> x, y = m # Python style says, we ought not use parentheses here
>>> x
'have'
>>> y
'fun'The above is equivalent to the following:
>>> m = [ 'have', 'fun' ]
>>> x = m[0]
>>> y = m[1]
>>> x
'have'
>>> y
'fun'In fact, we can do the same with other kinds of sequences:
>>> addr = 'monty@python.org'
>>> uname, domain = addr.split('@')Dictionaries and Tuples
You can use the dictionary method .item() to return a list of tuples
representing the key-value pairs in the dictionary:
>>> d = {'a':10, 'b':1, 'c':22}
>>> t = list(d.items())
>>> print(t)
[('b', 1), ('a', 10), ('c', 22)]This is particularly useful if you need to output the contents of dictionary sorted by key:
>>> d = {'a':10, 'b':1, 'c':22}
>>> t = list(d.items())
>>> t
[('b', 1), ('a', 10), ('c', 22)]
>>> t.sort()
>>> t
[('a', 10), ('b', 1), ('c', 22)]Multiple Assignments with Dictionaries
Combining the .items() method with a for loop gives you a nice coding
patterns for traversing the keys and values of a dictionary in a single loop
(and sorting them by e.g. value):
>>> d = {'a':10, 'b':1, 'c':22}
>>> l = list()
>>> for key, val in d.items() :
... l.append( (val, key) )
...
>>> l
[(10, 'a'), (22, 'c'), (1, 'b')]
>>> l.sort(reverse=True)
>>> l
[(22, 'c'), (10, 'a'), (1, 'b')]
>>>The following example again takes a text file and outputs a nice frequency analysis utilising the techniques and patterns outlined above:
fname = input('Enter the file name: ')
try:
fhand = open(fname)
except:
print('File cannot be opened:', fname)
exit()
for line in fhand:
line = line.translate(str.maketrans('', '', string.punctuation))
line = line.lower()
words = line.split()
for word in words:
if word not in counts:
counts[word] = counts.get(word,0) + 1
# Sort the dictionary by value
lst = list()
for key, val in list(counts.items()):
lst.append((val, key))
lst.sort(reverse=True)
# output the 10 most frequent words
for key, val in lst[:10]:
print(key, val)Using Tuples as Keys in Dictionaries
Because lists are not hashable, you need to use tuples if you want to create what’s know as a composite key in a dictionary. Think of a phonebook as dictionary with a composite key (first name, name) mapped to numbers:
directory[last,first] = numberTraversing this dictionary would look like this:
for last, first in directory:
print(first, last, directory[last,first])How to Choose the Right Data Structure
Say you need a data structure to store a collection of customer records. The consideration you need to make before choosing the data structure are the following:
- If the collection won’t change size (no need to add/delete customers) or you don’t need to shuffle them around within the collection, then tuples will work. Otherwise, you’ll need a list or a dictionary.
- If you need order in your collection, you should opt for a list or a tuple.
- Generally, tuples are less popular than lists, but in some cases, tuples can
be very helpful:
- Sometimes, like a return statement, it is syntactically simpler to create a tuple than a list. In other contexts, you might prefer a list.
- If you want to use a sequence as a dictionary key, you have to use an immutable type like a tuple or string.
- If you are passing a sequence as an argument to a function, using tuples reduces the potential for unexpected behaviour due to aliasing.
While tuples are immutable and thus don’t provide methods such as .sort() or
.reverse(), you can still use the built-in functions sorted and reversed
to do the job.
Exercise 10.1
Revise a previous program as follows: Read and parse the “From” lines and pull out the addresses from the line. Count the number of messages from each person using a dictionary.
After all the data has been read, print the person with the most commits by creating a list of (count, email) tuples from the dictionary. Then sort the list in reverse order and print out the person who has the most commits.
Solution
fname = input('Enter the file name: ')
try:
fhand = open(fname)
except:
print('File cannot be opened:', fname)
exit()
email_count = dict()
for line in fhand:
if not line.startswith('From ') : continue
words = line.split()
for word in words:
if "@" in word:
email_count[word] = email_count.get(word,0) + 1
lst = list()
for k, v in list(email_count.items()):
lst.append((v, k))
lst.sort(reverse=True)
res = lst[0]
print(res[1], res[0])Exercise 10.2
This program counts the distribution of the hour of the day for each of the messages. You can pull the hour from the “From” line by finding the time string and then splitting that string into parts using the colon character. Once you have accumulated the counts for each hour, print out the counts, one per line, sorted by hour as shown below.
Solution
fname = input('Enter the file name: ')
try:
fhand = open(fname)
except:
print('File cannot be opened:', fname)
exit()
hour_count = dict()
for line in fhand:
if not line.startswith('From ') : continue
words = line.split()
for word in words:
if not ":" in word : continue
hour = word[:2]
hour_count[hour] = hour_count.get(hour,0) + 1
for k, v in hour_count.items():
print(k, v)Exercise 10.3
Write a program that reads a file and prints the letters in decreasing order of frequency. Your program should convert all the input to lower case and only count the letters a-z. Your program should not count spaces, digits, punctuation, or anything other than the letters a-z. Find text samples from several different languages and see how letter frequency varies between languages. Compare your results with the tables at https://wikipedia.org/wiki/Letter%5Ffrequencies.
Solution
import string
fname = input('Enter the file name: ')
try:
fhand = open(fname)
except:
print('File cannot be opened:', fname)
exit()
char_count = dict()
for line in fhand:
line = line.rstrip()
line = line.translate(line.maketrans('', '', string.punctuation))
line = line.lower()
words = line.split()
for word in words:
for char in word:
char_count[char] = char_count.get(char,0) + 1
lst = list()
for k, v in char_count.items():
lst.append((v, k))
lst.sort(reverse=True)
char_sum = 0
for i in lst:
char_sum += i[0]
for i in lst:
letter = i[1]
freq = i[0]
rel_freq = freq / char_sum
print(letter, freq, rel_freq)Web Data
Regular Expressions
Until now, you know how to use built-in functions to extract text from a file or
a line that interests us. There is a thing called regular expressions that
does this job even better. Let’s import the re library and make a trivial use
of its search() function.
# Search for lines that contain 'From'
import re
hand = open('mbox-short.txt')
for line in hand:
line = line.rstrip()
if re.search('From:', line):
print(line)We can amend the code above using the ^ character to match the beginning of a
line. Let’s use this to match not all lines that contain “From:”, but only those
where it stands at the beginning of a line:
# Search for lines that start with 'From'
import re
hand = open('mbox-short.txt')
for line in hand:
line = line.rstrip()
if re.search('^From:', line):
print(line)Character Matching
The most commonly used special character is the period (.), which matches
any character (thus, it is a wild card character). Then, there is the +
character (match one-or-more characters) and the * character (match
zero-or-more characters). You can use these to further narrow done what lines we
are matching:
# Search for lines that start with From and have an at sign
import re
hand = open("mbox-short.txt")
for line in hand:
line = line.rstrip()
if re.search("^From:.+@", line):
print(line)The search string ^From:.+@ will match all lines that start with “From:”,
followed by one or more characters (.+), followed by ”@“. For instance, this
code will match the following line:
From: stephen.marquard@uct.ac.za.+ is greedy, i.e. they always match the largest string possible, as shown
below:
From: stephen.marquard@uct.ac.za, csev@umich.edu, and cwen@iupui.eduTo turn off the greedy behaviour, add a ? after the * or the +:
# Search for lines that start with From and have an at sign (non-greedy)
import re
hand = open('mbox-short.txt')
for line in hand:
line = line.rstrip()
if re.search('^From:.+?@', line):
print(line)Extracting Data
In order to extract data using regular expressions, you can use the findall()
method which searches the string in the second argument and returns a list of
list of every string it matches. We can use this to extract e-mail dresses:
import re
s = 'A message from csev@umich.edu to cwen@iupui.edu about meeting @2PM'
lst = re.findall('\S+@\S+', s)
print(lst)The output in this case would be:
['csev@umich.edu', 'cwen@iupui.edu']The regular expression above matches any substring that has at least one or more
non-whitespace character (\S+), followed by an ”@”, followed by at least one
or more non-whitespace character (since it is greedy-matching, as many
non-whitespace characters as possible). Using this to extract e-mail address
from our e-mail file would look like this:
# Search for lines that have an at sign between characters
import re
hand = open("mbox-short.txt")
for line in hand:
line = line.rstrip()
x = re.findall("\S+@\S+", line)
# print only lines where we find at least one e-mail address
if len(x) > 0:
print(x)['wagnermr@iupui.edu']
['cwen@iupui.edu']
['<postmaster@collab.sakaiproject.org>']
['<200801032122.m03LMFo4005148@nakamura.uits.iupui.edu>']
['<source@collab.sakaiproject.org>;']
['<source@collab.sakaiproject.org>;']
['<source@collab.sakaiproject.org>;']
['apache@localhost)']
['source@collab.sakaiproject.org;']Some of the e-mail addresses seem to have ”<” or ”>” characters at the beginning or the end, so you need to specify that you are only interested in the part of the string that starts or ends with a letter or a number. You can do this using square brackets in which we indicate a set of multiple acceptable characters you want to match:
# Search for lines that have an at sign between characters
# The characters must be a letter or number
import re
hand = open('mbox-short.txt')
for line in hand:
line = line.rstrip()
x = re.findall('[a-zA-Z0-9]\S+@\S+[a-zA-Z]', line)
if len(x) > 0:
print(x)...
['wagnermr@iupui.edu']
['cwen@iupui.edu']
['postmaster@collab.sakaiproject.org']
['200801032122.m03LMFo4005148@nakamura.uits.iupui.edu']
['source@collab.sakaiproject.org']
['source@collab.sakaiproject.org']
['source@collab.sakaiproject.org']
['apache@localhost']Combining Searching and Extracting
Let’s say you are interested in the following lines:
X-DSPAM-Confidence: 0.8475
X-DSPAM-Probability: 0.0000The following regular expression will do the job:
# Search for lines that start with 'X' followed by any non
# whitespace characters and ':'
# followed by a space and any number.
# The number can include a decimal.
import re
hand = open('mbox-short.txt')
for line in hand:
line = line.rstrip()
if re.search('^X\S*: [0-9.]+', line):
print(line)Note that inside the square brackets, the period matches an actual period (i.e. it is not a wildcard character between the square brackets).
But let’s say you only want to extract the numbers. Then the following code will do the job:
# Search for lines that start with 'X' followed by any
# non whitespace characters and ':' followed by a space
# and any number. The number can include a decimal.
# Then print the number if it is greater than zero.
import re
hand = open('mbox-short.txt')
for line in hand:
line = line.rstrip()
x = re.findall('^X\S*: ([0-9.]+)', line)
if len(x) > 0:
print(x)As you can inspect above, normal brackets, i.e. =()=, mark the part of the marched expression that you want to extract to the list.
Now you can also use regular expressions to redo an exercise from earlier where the aim was to extract the time of day of each e-mail message:
# Search for lines that start with From and a character
# followed by a two digit number between 00 and 99 followed by ':'
# Then print the number if it is greater than zero
import re
hand = open('mbox-short.txt')
for line in hand:
line = line.rstrip()
x = re.findall('^From .* ([0-9][0-9]):', line)
if len(x) > 0: print(x)['09']
['18']
['16']
['15']
...Escape Character
Since there are a lot of special characters in regular expressions, what if you
want to match one of those in the “normal” way. You can do this by simply
prefixing that character with a \. So, in order to find the dollar sign, do:
import re
x = 'We just received $10.00 for cookies.'
y = re.findall('\$[0-9.]+',x)Summary
| RegEx | Description |
|---|---|
^ | matches the beginning of the line |
$ | matches the end of the line |
. | matches any character |
\s | matches a whitespace character |
\S | matches a non-whitespace character |
* | applies to immediately preceding character and indicates to match zero or more times |
*? | applies to immediately preceding character and indicates to match zero or more times in ‘non-greedy mode’ |
+ | applies to immediately preceding character and indicates to match one or more times |
+? | applies to immediately preceding character and indicates to match one or more times in ‘non-greedy mode’ |
? | applies to immediately preceding character and indicates to match zero or one time |
?? | applies to immediately preceding character and indicates to match zero or one time in ‘non-greedy mode’ |
[aeiou] | matches any single character as long as it is in the specified set |
[a-z0-9] | ranges are specified using the minus sign (here, lowercase letter or digit) |
[^A-Za-z] | when the first character in a set is the caret, the logic is inverted (here, match anything but upper- or lowercase letters) |
( ) | parentheses denote the part of the regular expression that is supposed to be extracted |
\b | matches the boundary (or empty string) only at the end or start of a word |
\B | matches the empty string, but not at the |
\d | matches any digit (i.e. 0-9) |
\D | matches any non-digit |
Exercise 11.1
Write a simple program to simulate the operation of the grep command on Unix. Ask the user to enter a regular expression and count the number of lines that matched the regular expression:
$ python grep.py
Enter a regular expression: ^Author
mbox.txt had 1798 lines that matched ^Author
$ python ex11_1.py
Enter a regular expression: ^X-
mbox.txt had 14368 lines that matched ^X-
$ python ex11_1.py
Enter a regular expression: java$
mbox.txt had 4175 lines that matched java$Solution
import re
regexp = input('Enter a regular expression: ')
fhand = open('mbox.txt')
count = 0
for line in fhand:
x = re.findall(regexp, line)
if len(x) > 0 : count += 1
print('mbox.txt had %d lines that matched %s' % (count, regexp))Exercise 11.2
Write a program to look for lines of the form:
New Revision: 39772Extract the number from each of the lines using a regular expression and the
findall() method. Compute the average of the numbers and print out the average
as an integer.
Enter file:mbox.txt
38549
Enter file:mbox-short.txt
39756Solution
import re
fname = input("Enter file:")
fhand = open(fname)
lst = list()
for line in fhand:
x = re.findall('^New Revision: ([0-9]+)', line)
if len(x) == 1:
lst.append(int(x[0]))
total = sum(lst)
avg = total / len(lst)
print(int(avg))Network Programming
A Simple Web Browser
The following code makes a connection to a web server (in this case
data.pr4e.org on port 80). It follows the Hypertext Transfer Protocol (HTTP)
to request a document and display what the server responds:
import socket
mysock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
mysock.connect(('data.pr4e.org', 80))
cmd = 'GET http://data.pr4e.org/romeo.txt HTTP/1.0\r\n\r\n'.encode()
mysock.send(cmd)
while True:
data = mysock.recv(512)
if len(data) < 1:
break
print(data.decode(),end='')
mysock.close()The \r\n\r\n signifies as much as “nothing between two end of lines (EOLs)” or
a blank line.
Once the code sends the blank line, your loop receives data in 512-character chunks from the socket and prints it out until there is no more data to read (i.e. =recv()= returns an empty string)
This is the output:
HTTP/1.1 200 OK
Date: Tue, 24 Mar 2020 14:50:42 GMT
Server: Apache/2.4.18 (Ubuntu)
Last-Modified: Sat, 13 May 2017 11:22:22 GMT
ETag: "a7-54f6609245537"
Accept-Ranges: bytes
Content-Length: 167
Cache-Control: max-age=0, no-cache, no-store, must-revalidate
Pragma: no-cache
Expires: Wed, 11 Jan 1984 05:00:00 GMT
Connection: close
Content-Type: text/plain
But soft what light through yonder window breaks
It is the east and Juliet is the sun
Arise fair sun and kill the envious moon
Who is already sick and pale with griefYou need the decode() and encode() methods to convert strings to bytes
objects (which is needed by HTTP) and back again. You can also use the
b'some_string' notation
Using the following code, you can retrieve images from the web:
import socket
import time
HOST = 'data.pr4e.org'
PORT = 80
mysock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
mysock.connect((HOST, PORT))
mysock.sendall(b'GET http://data.pr4e.org/cover3.jpg HTTP/1.0\r\n\r\n')
count = 0
picture = b""
while True:
data = mysock.recv(5120)
if len(data) < 1: break
#time.sleep(0.25)
count = count + len(data)
print(len(data), count)
picture = picture + data
mysock.close()
# Look for the end of the header (2 CRLF)
pos = picture.find(b"\r\n\r\n")
print('Header length', pos)
print(picture[:pos].decode())
# Skip past the header and save the picture data
picture = picture[pos+4:]
fhand = open("stuff.jpg", "wb")
fhand.write(picture)
fhand.close()Running the code above will give you the following output alongside a new file
called stuff.jpg in the directory you ran the code from.
5120 5120
5120 10240
4240 14480
5120 19600
...
5120 214000
3200 217200
5120 222320
5120 227440
3167 230607
Header length 393
HTTP/1.1 200 OK
Date: Wed, 11 Apr 2018 18:54:09 GMT
Server: Apache/2.4.7 (Ubuntu)
Last-Modified: Mon, 15 May 2017 12:27:40 GMT
ETag: "38342-54f8f2e5b6277"
Accept-Ranges: bytes
Content-Length: 230210
Vary: Accept-Encoding
Cache-Control: max-age=0, no-cache, no-store, must-revalidate
Pragma: no-cache
Expires: Wed, 11 Jan 1984 05:00:00 GMT
Connection: close
Content-Type: image/jpegSometimes our connection is not fast enough to fill all the 5120 bytes each time
your program asks for it. Thus, we can just give it a bit more time by
uncommenting the call to time.sleep() in the code above. With this delay, you
will always get your full 5120 bytes and only one remainder of 207 bytes:
5120 5120
5120 10240
5120 15360
...
5120 225280
5120 230400
207 230607
Header length 393
HTTP/1.1 200 OK
Date: Wed, 11 Apr 2018 21:42:08 GMT
Server: Apache/2.4.7 (Ubuntu)
Last-Modified: Mon, 15 May 2017 12:27:40 GMT
ETag: "38342-54f8f2e5b6277"
Accept-Ranges: bytes
Content-Length: 230210
Vary: Accept-Encoding
Cache-Control: max-age=0, no-cache, no-store, must-revalidate
Pragma: no-cache
Expires: Wed, 11 Jan 1984 05:00:00 GMT
Connection: close
Content-Type: image/jpegRetrieving Webpages Using urllib
Whilst it is possible to receive data via the socket library, it is much easier
using the urllib library which retrieves webpages much like a file. So, in
order to retrieve the same file as above (romeo.txt), you can write the
following code:
import urllib.request
fhand = urllib.request.urlopen('http://data.pr4e.org/romeo.txt')
for line in fhand:
print(line.decode().strip())But soft what light through yonder window breaks
It is the east and Juliet is the sun
Arise fair sun and kill the envious moon
Who is already sick and pale with griefA bit simpler, isn’t it?
Retrieving Binary Files Using urllib
In order to retrieve a non-text (i.e. binary) file (e.g. image or video), first write the entire contents of the document into a string variable and then write that information to a local file as follows:
import urllib.request, urllib.parse, urllib.error
img = urllib.request.urlopen('http://data.pr4e.org/cover3.jpg').read()
fhand = open('cover3.jpg', 'wb')
fhand.write(img)
fhand.close()If you are dealing with a very large file, you might run into problems because your computer is running out of (primary) memory to store all the data in. This is where buffering comes into play. In the example below, the code only reads 100,000 characters at a time into your computer’s memory:
import urllib.request, urllib.parse, urllib.error
img = urllib.request.urlopen('http://data.pr4e.org/cover3.jpg')
fhand = open('cover3.jpg', 'wb')
size = 0
while True:
info = img.read(100000)
if len(info) < 1: break
size = size + len(info)
fhand.write(info)
print(size, 'characters copied.')
fhand.close()Parsing HTML Using Regular Expressions
Most websites use Hypertext Markup Language (HTML) for displaying information.
With some knowledge of how this language is specified, you can use regular
expressions (along with urllib) to extract the parts that interest you. This
activity is called webscraping.
Here is some simple HTML-code:
<h1>The First Page</h1>
<p>
If you like, you can switch to the
<a href="http://www.dr-chuck.com/page2.htm">
Second Page</a>.
</p>Say, you want to extract all link from the webpage, this well-formed regular expression will do the job:
href="http[s]?://.+?"Adding parentheses around the part that interests you and constructing a scaffolding in Python to extract the webpage yields the following program:
# Search for link values within URL input
import urllib.request, urllib.parse, urllib.error
import re
import ssl
# Ignore SSL certificate errors
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
url = input('Enter - ')
html = urllib.request.urlopen(url).read()
links = re.findall(b'href="(http[s]?://.*?)"', html)
for link in links:
print(link.decode())The ssl library allows this program to access websites which are served via
the secure (read encrypted) hypertext transport protocol (HTTPS). Running the
code gives the follwing output:
Enter - https://docs.python.org
https://docs.python.org/3/index.html
https://www.python.org/
https://docs.python.org/3.8/
https://docs.python.org/3.7/
https://docs.python.org/3.5/
https://docs.python.org/2.7/
https://www.python.org/doc/versions/
https://www.python.org/dev/peps/
https://wiki.python.org/moin/BeginnersGuide
https://wiki.python.org/moin/PythonBooks
https://www.python.org/doc/av/
https://www.python.org/
https://www.python.org/psf/donations/
http://sphinx.pocoo.org/There is a caveat here, however. Regular expressions work well with nicely
formatted, predictable HTML-code. This is not the reality of the web. For real
webscraping, you need a robust HTML parsing library. Enter BeautifulSoup.
Parsing HTML Using BeautifulSoup
After installing BeautifulSoup to your Python interpreter (in my case
Anaconda), you can import it and use it to extract the href attributes from
the anchor (a) tags:
import urllib.request, urllib.parse, urllib.error
from bs4 import BeautifulSoup
import ssl
# Ignore SSL certificate errors
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
url = input('Enter - ')
html = urllib.request.urlopen(url, context=ctx).read()
soup = BeautifulSoup(html, 'html.parser')
# Retrieve all of the anchor tags
tags = soup('a')
for tag in tags:
print(tag.get('href', None))The program prompts you for a web address, reads all the data displayed there,
passes it onto the parser from BeautifulSoup, and then retrieves all of the
anchor tags printing only the href attribute for each tag:
Enter - https://docs.python.org
genindex.html
py-modindex.html
https://www.python.org/
#
whatsnew/3.6.html
whatsnew/index.html
tutorial/index.html
library/index.html
reference/index.html
using/index.html
howto/index.html
installing/index.html
distributing/index.html
extending/index.html
c-api/index.html
faq/index.html
py-modindex.html
genindex.html
glossary.html
search.html
contents.html
bugs.html
about.html
license.html
copyright.html
download.html
https://docs.python.org/3.8/
https://docs.python.org/3.7/
https://docs.python.org/3.5/
https://docs.python.org/2.7/
https://www.python.org/doc/versions/
https://www.python.org/dev/peps/
https://wiki.python.org/moin/BeginnersGuide
https://wiki.python.org/moin/PythonBooks
https://www.python.org/doc/av/
genindex.html
py-modindex.html
https://www.python.org/
#
copyright.html
https://www.python.org/psf/donations/
bugs.html
http://sphinx.pocoo.org/You can also use BeautifulSoup to pull out various parts of each tag:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import ssl
# Ignore SSL certificate errors
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
url = input('Enter - ')
html = urlopen(url, context=ctx).read()
soup = BeautifulSoup(html, "html.parser")
# Retrieve all of the anchor tags
tags = soup('a')
for tag in tags:
# Look at the parts of a tag
print('TAG:', tag)
print('URL:', tag.get('href', None))
print('Contents:', tag.contents[0])
print('Attrs:', tag.attrs)Enter - http://www.dr-chuck.com/page1.htm
TAG: <a href="http://www.dr-chuck.com/page2.htm">
Second Page</a>
URL: http://www.dr-chuck.com/page2.htm
Content: ['\nSecond Page']
Attrs: [('href', 'http://www.dr-chuck.com/page2.htm')]These examples only scratch the surface of what is possible with
BeautifulSoup.
Exercise 12.1
Change the socket program from earlier to prompt the user for the URL so it can
read any web page. You can use split('/') to break the URL into its component
parts so you can extract the host name for the socket connect call. Add error
checking using try and except to handle the condition where the user enters
an improperly formatted or non-existent URL.
Solution
import re
import socket
try:
url = input('Enter URL - ')
host = re.findall('(?:[-.a-zA-Z0-9]+)', url)[1]
mysock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
mysock.connect((host, 80))
cmd = str('GET ' + url + ' HTTP/1.0\r\n\r\n').encode()
mysock.send(cmd)
while True:
data = mysock.recv(512)
if len(data) < 1:
break
print(data.decode(), end='')
mysock.close()
except:
print("There must be somthing wrong with the URL you typed in")Exercise 12.2
Change your socket program so that it counts the number of characters it has received and stops displaying any text after it has shown 3000 characters. The program should retrieve the entire document and count the total number of characters and display the count of the number of characters at the end of the document.
Solution
import re
import socket
# use larger file for testing 3000 limit
url = 'http://data.pr4e.org/mbox.txt'
host = re.findall('(?:[-.a-zA-Z0-9]+)', url)[1]
mysock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
mysock.connect((host, 80))
cmd = str('GET ' + url + ' HTTP/1.0\r\n\r\n').encode()
mysock.send(cmd)
document = b''
for i in range(5):
data = mysock.recv(600)
if len(data) < 1:
break
document = document + data
mysock.close()
print(document.decode())
print('Total number of received characters: ', len(document))Exercise 12.3
Use urllib to replicate the previous exercise of (1) retrieving the document
from a URL, (2) displaying up to 3000 characters, and (3) counting the overall
number of characters in the document. Don’t worry about the headers for this
exercise, simply show the first 3000 characters of the document contents.
Solution
import urllib.request
fhand = urllib.request.urlopen('http://data.pr4e.org/mbox.txt')
doc = str()
for line in fhand:
line = line.decode()
doc = doc + line
if len(doc) > 3000:
break
print(doc[:3000])Exercise 12.4
Change the link-extracting program from above to extract and count paragraph (p) tags from the retrieved HTML document and display the count of the paragraphs as the output of your program. Do not display the paragraph text, only count them. Test your program on several small web pages as well as some larger web pages.
Solution
import urllib.request, urllib.parse, urllib.error
from bs4 import BeautifulSoup
import ssl
# Ignore SSL certificate errors
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
url = input('Enter - ')
html = urllib.request.urlopen(url, context=ctx).read()
soup = BeautifulSoup(html, 'html.parser')
# Retrieve all of the anchor tags
tags = soup('p')
count = 0
for tag in tags:
count += 1
print(count)Exercise 12.5
(Advanced) Change the socket program so that it only shows data after the
headers and a blank line have been received. Remember that recv receives
characters (newlines and all), not lines.
Solution
import re
import socket
url = 'http://data.pr4e.org/mbox-short.txt'
host = re.findall('(?:[-.a-zA-Z0-9]+)', url)[1]
mysock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
mysock.connect((host, 80))
cmd = str('GET ' + url + ' HTTP/1.0\r\n\r\n').encode()
mysock.send(cmd)
count = 0
while True:
# increase buffer size to include header in char string
data = mysock.recv(5120)
msg = data.decode()
if not data:
break
if count == 0:
header_end_pos = msg.find('\r\n\r\n') + 4
print(msg[header_end_pos:])
else:
print(msg)
mysock.close()Using Web Services
Parsing HTML is not very efficient as its made for the consumption by humans, not programs. There are two common formats that you are used to exchange data between machines over the web: eXtensible Markup Langueage (XML) and JavaScript Object Notation (JSON).
eXtensible Markup Language (XML)
You can think of XML as a more structured version of HTML which is less forgiving about formal mistakes. Here is a sample XML document:
<person>
<name>Chuck</name>
<phone type="intl">
+1 734 303 4456
</phone>
<email hide="yes" />
</person>It is often useful to think of an XML document as a tree. There is a top or
parent element (here: person) that has three children (e.g. =phone=).
![[xml-tree.svg” caption=“Figure 7: XNL as a structured tree” >}}
Parsing XML
The following code shows how to parse and extract some data from an piece of data formatted like XML:
import xml.etree.ElementTree as ET
data = '''
<person>
<name>Chuck</name>
<phone type="intl">
+1 734 303 4456
</phone>
<email hide="yes" />
</person>'''
tree = ET.fromstring(data)
print('Name:', tree.find('name').text)
print('Attr:', tree.find('email').get('hide'))The .fromstring() method converts the string representation of the XML into a
tree of XML elements for which we have several methods to extract the
interesting parts. The find function for instance searches through the XML
tree and returns the element that matches the specified tag.
What the built-in parser ElementTree allows you to do is to extract data from
XML documents without worrying too much about the exact syntax of XML.
Looping Through Nodes
Consider the following program which loops through the multiple user nodes of
an XML tree.
import xml.etree.ElementTree as ET
input = '''
<stuff>
<users>
<user x="2">
<id>001</id>
<name>Chuck</name>
</user>
<user x="7">
<id>009</id>
<name>Brent</name>
</user>
</users>
</stuff>'''
stuff = ET.fromstring(input)
# remember: don't include top-level element
lst = stuff.findall('users/user')
print('User count:', len(lst))
for item in lst:
print('Name', item.find('name').text)
print('Id', item.find('id').text)
print('Attribute', item.get('x'))The .findall() method returns a Python list of subtrees that represent the
user structure of the XML tree. Looping through the user nodes, the program
then yields the following output:
User count: 2
Name Chuck
Id 001
Attribute 2
Name Brent
Id 009
Attribute 7Here, you have to remember to give provide all parent elements except the top
level element, (e.g. =users/user=) and not stuff/users/user. To highlight
this point, see the code below:
import xml.etree.ElementTree as ET
input = '''
<stuff>
<users>
<user x="2">
<id>001</id>
<name>Chuck</name>
</user>
<user x="7">
<id>009</id>
<name>Brent</name>
</user>
</users>
</stuff>'''
stuff = ET.fromstring(input)
lst = stuff.findall('users/user')
print('User count:', len(lst))
lst2 = stuff.findall('user')
print('User count:', len(lst2))User count: 2
User count: 0lst2 is empty because it looked for user elements which are not nested
within the top level stuff element (where there are none of).
JavaScript Object Notation (JSON)
The JSON format was inspired by the object and array format used in JavaScript. But since Python is older, its syntax for dictionaries and lists influenced the specification of the JSON syntax, which is why JSON is nearly identical to a combination of Python lists and dictionaries:
{
"name" : "Chuck",
"phone" : {
"type" : "intl",
"number" : "+1 734 303 4456"
},
"email" : {
"hide" : "yes"
}
}Parsing JSON
Generally, JSON data is best thought of in Python as dictionaries nested in
lists. JSON tends be more succint than XML but also less self-describing which
is problematic if the data structure is unclear to you. Let’s see an example of
how to use Python’s built-in json library:
import json
data = """
[
{ "id" : "001",
"x" : "2",
"name" : "Chuck"
} ,
{ "id" : "009",
"x" : "7",
"name" : "Brent"
}
]"""
info = json.loads(data)
print("User count:", len(info))
for item in info:
print("Name", item["name"])
print("Id", item["id"])
print("Attribute", item["x"])In the above example, json.loads() is a python list which (by virtue of being
iterable) you can traverse by using a for loop.
While there is a trend towards JSON in web services since it maps cleanly onto native dtat structures in many programming languages, there are some applications (such as word processors) where XML retains its advantage as a more self-describing but complex data structure.
Application Programming Interfaces (APIs)
You can now exchange data between applications via HTTP, XML or JSON. The next step would be to describe a “contract” between different applications for the data exchange. These application-to-application contracts are called Application Programming Interfaces (APIs). Say, you want to access data about user interaction in certain subreddits. In this case, you would have to stick to the usage specified in Reddit’s documentation of its API.
The course text gives two examples of API usage (Google Maps and Twitter) that I did not find particularly interesting which is why I left them out and directly went to the exercises in the autograder.
Databases
Object-Oriented Programming (OOP)
Managing Larger Programs
As programs grow in size and complexity, good segmentation of its parts becomes more important. In a way, OOP is a way to arrange code enabling you to focus on its 50 lines that do the particular thing that’s interesting to you or needs fixing while ignoring the other 999,950 lines of code that do something else.
Using Objects
Turns out, you have been using objects all the time while constructing Python programs:
stuff = list() # 1
stuff.append("python") # 2
stuff.append("chuck") # 3
stuff.sort() # 4
print(stuff[0]) # 5
print(stuff.__getitem__(0)) # 6
print(list.__getitem__(stuff, 0)) # 7From the perspective of OOP, what is happening in the code above? The first line
constructs an object of type list, the second and third lines call the
.append() method, the fourth line calls the .sort() method, and the fifth
line retrieves the item at index 0.
The sixth and seventh lines of the code snippet are also retrieving the item at
index 0 of the list, but there are more verbose ways of doing so. You can find
about more about the .__getitem__() method by looking up the capabilities of
any given object like so:
>>> stuff = list()
>>> dir(stuff)['__add__', '__class__', '__contains__', '__delattr__',
'__delitem__', '__dir__', '__doc__', '__eq__',
'__format__', '__ge__', '__getattribute__', '__getitem__',
'__gt__', '__hash__', '__iadd__', '__imul__', '__init__',
'__iter__', '__le__', '__len__', '__lt__', '__mul__',
'__ne__', '__new__', '__reduce__', '__reduce_ex__',
'__repr__', '__reversed__', '__rmul__', '__setattr__',
'__setitem__', '__sizeof__', '__str__', '__subclasshook__',
'append', 'clear', 'copy', 'count', 'extend', 'index',
'insert', 'pop', 'remove', 'reverse', 'sort']Starting with Programs
In its most basic form, a program takes an input, processes it and produces some output. Consider, for instance, the following simple elevator conversion program:
usf = input('Enter the US Floor Number: ')
wf = int(usf) - 1
print('Non-US Floor Number is',wf)One way to think about OOP is that it segments your program into zones. Each zone contains some code and data and has well-defined interactions with the outside world and the other zones of your program. Looking back at the link extractor program, you see that it is constructed by connecting different objects together to accomplish a task:
import urllib.request, urllib.parse, urllib.error
from bs4 import BeautifulSoup
import ssl
# Ignore SSL certificate errors
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
url = input('Enter - ')
html = urllib.request.urlopen(url, context=ctx).read()
soup = BeautifulSoup(html, 'html.parser')
# Retrieve all of the anchor tags
tags = soup('a')
for tag in tags:
print(tag.get('href', None))The program reads the URL into a string and passes it into urllib to retrieve
the data from the web. Next, the string returned by urllib is handed to
BeautifulSoup for parsing. BeautifulSoup makes use of the object html.parser
and returns an object. Next, the program calls the .tags() method on the
returned object, returning a dictionary of tag objects. Looping through this
dictionary, the program then uses the .get() method to print out the href
attribute of each tag. You can draw a picture of this program visualizing how
its objects work together:
![[oop.svg” caption=“Figure 8: A Program as a Network of Objects” >}}
The key here is to understand the program as a network of interacting objects along with a set of rules orchestrating the movement of information between those objects.
Subdividing a Problem
A key advantage of OOP is that it hides away complexity when you don’t need it
but shows you where to find it if you do. For instance, you don’t need to know
how the urllib objects work internally in order to use them to retrieve some
data from the internet. This allows you to focus.
Our First Python Object
In it most basic sense, an object is simply some code in addition to data structures. On the code part of things, objects contain functions (which are called methods). The data part of an object is called attributes.
Using the class keyword, you can define the data and the code that make up
each object.
class PartyAnimal:
x = 0
def party(self):
self.x = self.x + 1
print("So far", self.x)
an = PartyAnimal()
an.party()
an.party()
an.party()
PartyAnimal.party(an)Methods are defined like functions using the def keyword. In the case above,
you have one attribute (x) and one method (party). In general, methods have
a special first parameter that, by convention, is called self.
It is important to remember that the class keyword does not create an object
(just like the def keyword does not cause the function code in its body to be
executed). Rather, the class keyword defines a template specifying what code
and data will be contained in the each object of type PartyAnimal.
Thus, the first executable line of code in the little program above is:
an.party()Here, the object or instance is created. When the party method of the object is called, the following lines will be executed:
self.x = self.x + 1The first parameter of the method is called self by convention. You are using
the dot operator to access the “x within self”. Every time the method
party() is called, its internal x value is incremented by 1 and printed out.
PartyAnimal.party(an) is a way to access code from within the class and
explicitly pass the object pointer an as the first parameter (this is what
will be the self in the party() method). Thus, an.party() is just a
shorthand way for writing the same thing.
Running the problem gives:
So far 1
So far 2
So far 3
So far 4In summary, the object is constructed before its class-internal method is called
four times both incrementing and printing the value for x within the an
object of class PartyAnimal.
Classes as Types
in Python, all variables have a particular type that we can access with the
built-in type function. The built-in dir function lets you examine the
capabilities of a variable. Let’s try those with your custom-made class:
class PartyAnimal:
x = 0
def party(self) :
self.x = self.x + 1
print("So far",self.x)
an = PartyAnimal()
print ("Type", type(an))
print ("Dir ", dir(an))
print ("Type", type(an.x))
print ("Type", type(an.party))Executing the program yields the following output:
Type <class '__main__.PartyAnimal'>
Dir ['__class__', '__delattr__', ...
'__sizeof__', '__str__', '__subclasshook__',
'__weakref__', 'party', 'x']
Type <class 'int'>
Type <class 'method'>Using the class keyword, you have effectively created a new type. From the
output of the dir function, you can see both the x integer attribute and the
party method are available in the object.
Object Lifecycle
As your classes and objects become more complex, you need to think about what happens to its code and its data it is created and when it is destructed. The following code presents a class that creates awareness of theses moments of creation and destruction:
class PartyAnimal:
x = 0
def __init__(self):
print('I am constructed')
def party(self) :
self.x = self.x + 1
print('So far',self.x)
def __del__(self):
print('I am destructed', self.x)
an = PartyAnimal()
an.party()
an.party()
an = 42
print('an contains',an)Running the code gives:
I am constructed
So far 1
So far 2
I am destructed 2
an contains 42While Python constructs your object, it calls the __init__ method to give us a
chance to set up some initial values for the object. When you reassign an to
an integer, it throws away your object to make space for the new data. This is
why our destructor method __del__ is called. While you cannot stop the
destruction process here, you can do some necessary clean-up right before our
objects slips away into blissful non-existence. Destructor methods are much more
rarely used than constructor methods.
Multiple Instances
When constructing multiple objects from our class, you might want to set up different initial values for each of these objects. In order to do this, you can pass data to the constructors:
class PartyAnimal:
x = 0
name = ''
def __init__(self, nam):
self.name = nam
print(self.name,'constructed')
def party(self) :
self.x = self.x + 1
print(self.name,'party count',self.x)
s = PartyAnimal('Sally')
j = PartyAnimal('Jim')
s.party()
j.party()
s.party()In this case, the constructor has both a self parameter pointing to the
instance of the object and additional parameters that are passed into the
constructor as the object is being constructed, i.e. when you assign
PartyAnimal('some_string') to a variable.
Within the constructor, the second line assigns the parameter that was passed
into the constructor (nam) to the object’s name attribute.
Inheritance
OOP also gives you the ability to create new classes by simply extending exiting classes. By convention, the original class is called the parent class and the resulting class the child class.
To illustrate this, move the PartyAnimal class into its own file called
party.py. Next, you import that class in a new file as follows:
from party import PartyAnimal
class CricketFan(PartyAnimal): # extending the PartyAnimal class
points = 0
def six(self):
self.points = self.points + 6
self.party()
print(self.name,"points",self.points)
s = PartyAnimal("Sally")
s.party()
j = CricketFan("Jim")
j.party()
j.six()
print(dir(j))When defining the CricketFan as above, you are telling Python to inherit all
of the attributes (x) and methods (party) from the PartyAnimal class. For
instance, this allows you to call the party method from within the new six
method. As the program executes, s and j are created as independent
instances of PartyAnimal and CricketFan. In comparison, the j has one
additional method (six) and one additional attribute (points).
Sally constructed
Sally party count 1
Jim constructed
Jim party count 1
Jim party count 2
Jim points 6
['__class__', '__delattr__', ... '__weakref__',
'name', 'party', 'points', 'six', 'x']Summary
Reviewing the code block from the beginning of the chapter, you can now understand much better what is going on:
stuff = list() #1
stuff.append('python') #2
stuff.append('chuck') #3
stuff.sort() #4
print (stuff[0]) #5
print (stuff.__getitem__(0)) #6
print (list.__getitem__(stuff,0)) #7The first constructs a list object. You haven’t passed any parameters to the
constructor (named __init__) to set up internal attributes used to store the
list data. Next, the constructor returns an instance of the list object, you
assign it to the variable stuff.
The second and third lines call the append method with one parameter to add a
new item to the end of the list by updating the attributes within stuff. In
the fourth line, you call the sort method without any parameters to order the
data within the stuff object.
In the fifth line, you use the square brackets which are a shorthand for what’s
happening in the sixth or seventh line, i.e. calling the __getitem__ method of
the list class and passing the stuff object as the first and the position we
are looking for as the second parameter.
At the end of the program, the stuff object is discarded after calling the
destructor (named __del__) so that the object can clean up as necessary.
Using Databases and SQL
What is a database
A database is a file whose structure is optimised for storing data. Thus it lives on permanent storage, such that it persists after the program ends. There are many databases out there, but for this course we’ll stick to one that is already well-integrated into python, namely SQLite.
Database concepts
Think of a database as a spreadsheet with multiple sheets (tables). In each table, you have rows and columns. The corresponding, more technical terms are relation, tuple and /attribute.
Creating a Database Table
When creating a table in SQLite, we must already tell the database the names of all columns along with the type of data we intend to store in it. These are the datatypes supported by SQLite.
import sqlite3
# connect to the database or
# create it in current directory if it does not exist
conn = sqlite3.connect('music.sqlite')
# create a cursor (like a file handle)
cur = conn.cursor()
# delete existing instances of the table "Tracks"
cur.execute('DROP TABLE IF EXISTS Tracks')
# create a table with two columns:
# title (with data of type TEXT) and
# plays (with data of type INTEGER)
cur.execute('CREATE TABLE Tracks (title TEXT, plays INTEGER)')
conn.close()This is a visualisation of the database cursor:

Now, let’s add some data to the table:
import sqlite3
conn = sqlite3.connect('music.sqlite')
cur = conn.cursor()
# Here, you define a new row for the table "Tracks". Next, we define the fields
# we want to include (title, plays). (?, ?) defines that you are going to pass
# the actual values as a tuple to the execute() call
cur.execute('INSERT INTO Tracks (title, plays) VALUES (?, ?)',
('Thunderstruck', 20))
cur.execute('INSERT INTO Tracks (title, plays) VALUES (?, ?)',
('My Way', 15))
# force the data to be written to the database
conn.commit()
# you can loop through your database using the cursor
print('Tracks:')
cur.execute('SELECT title, plays FROM Tracks')
for row in cur:
print(row)
# delete the rows such that you can run the program over and over
cur.execute('DELETE FROM Tracks WHERE plays < 100')
conn.commit()
cur.close()The program above yields the following output:
Tracks:
('Thunderstruck', 20)
('My Way', 15)SQL Summary
Create a table
CREATE TABLE Tracks (title TEXT, plays INTEGER)Insert rows into table
INSERT INTO Tracks (title, plays) VALUES ('My Way', 15)Retrieve rows and columns from a table
SELECT * FROM Tracks WHERE title = 'My Way'- Using
*indicates that you want all the columns for each row that matches yourWHEREclause. - Other logical operations include
<,>,<=,>=,!= - You can also sort the requested rows:
SELECT title,plays FROM Tracks ORDER BY titleDelete rows
DELETE FROM Tracks WHERE title = 'My Way'Update column(s) within one or more rows
UPDATE Tracks SET plays = 16 WHERE title = 'My Way'-
Without a
WHEREclause, the update is performed on all rows in the tableThese four basic SQL commands (
INSERT,SELECT,UPDATE, andDELETE) allow the four basic operations needed to create and maintain data.
Spidering
In the following, I used an example that is related to my thesis in political science instead of the twitter spidering. Roughly the same features were implemented.
Basically, I scraped the events from this timeline and inserted them into a relational database with both one-to-many (categories, i.e. one category can apply to multiple events but an event can only be in one category) and many-to-many relationships (tags, i.e. one tag can apply to multiple events and an event can have multiple tags)
from bs4 import BeautifulSoup
import datetime
import re
import sqlite3
# downloaded html to be scraped
html = open("2013-2017-werkontrolliertwen.html", encoding="utf-8")
soup = BeautifulSoup(html, "html.parser")
# helper lists
titles = [] # list
types = [] # list
dates = [] # list
descriptions = [] # list
sources = [] # list of lists
tags = [] # list of lists
# create sqlite database and connect to it
conn = sqlite3.connect("timeline.db")
cur = conn.cursor()
# initialise db
cur.executescript(
"""
PRAGMA foreign_keys = ON;
CREATE TABLE IF NOT EXISTS categories (
id INTEGER PRIMARY KEY,
name TEXT UNIQUE);
CREATE TABLE IF NOT EXISTS tags (
id INTEGER PRIMARY KEY,
name TEXT UNIQUE);
CREATE TABLE IF NOT EXISTS events (
id INTEGER PRIMARY KEY,
title_de TEXT UNIQUE,
title_en TEXT UNIQUE,
start_date TEXT,
end_date TEXT,
description_de TEXT,
description_en TEXT,
category_id INTEGER,
FOREIGN KEY (category_id) REFERENCES categories(id));
CREATE TABLE IF NOT EXISTS event_tags (
event_id INTEGER,
tag_id INTEGER,
UNIQUE(event_id, tag_id),
FOREIGN KEY(event_id) REFERENCES events(id),
FOREIGN KEY(tag_id) REFERENCES tags(id))
"""
)
# loop through all the relevant divs
for block in soup.find_all(
"div", class_="timeline-block", id=re.compile("item"), limit=300
):
# add titles
title = block.contents[1].contents[0].get_text()
titles.append(title)
cur.execute(
""" INSERT OR IGNORE INTO events (title_de)
VALUES (?)""",
(title,),
)
# add categories
if "fa-calendar" in str(block):
category = "event"
types.append(category)
cur.execute(
""" INSERT OR IGNORE INTO categories (name) VALUES (?)""",
(category,),
)
cur.execute(" UPDATE events SET category_id = ? WHERE title_de = ?", (1, title))
elif "fa-tint" in str(block):
category = "revelation"
types.append(category)
cur.execute(
" INSERT OR IGNORE INTO categories (name) VALUES (?)",
(category,),
)
cur.execute(" UPDATE events SET category_id = ? WHERE title_de = ?", (2, title))
else:
category = "committee hearing"
types.append(category)
cur.execute(
""" INSERT OR IGNORE INTO categories (name) VALUES (?)""",
(category,),
)
cur.execute(" UPDATE events SET category_id = ? WHERE title_de = ?", (3, title))
# add dates
date_candidate = block.contents[1].contents[1]
# check whether date_candidate is in fact a date
if "timeline-date" in str(date_candidate):
# if yes, append the date to the list
date = datetime.datetime.strptime(date_candidate.get_text(), "%d.%m.%Y")
dates.append(date.date())
cur.execute(
" UPDATE events SET start_date = ? WHERE title_de = ?", (date.date(), title)
)
cur.execute(
" UPDATE events SET end_date = ? WHERE title_de = ?", (date.date(), title)
)
else:
# else, reuse the last valid date in the list
cur.execute(
" UPDATE events SET start_date = ? WHERE title_de = ?", (dates[-1], title)
)
cur.execute(
" UPDATE events SET end_date = ? WHERE title_de = ?", (dates[-1], title)
)
dates.append(dates[-1])
# add descriptions in German
# first, check whether block contains description
if "section summary" in str(block):
# if it does, find all instances and append them as a clean string to
# our list
for summary_block in block.find_all(class_="section summary"):
description = summary_block.get_text().replace("\n", "")
descriptions.append(description)
cur.execute(
" UPDATE events SET description_de = ? WHERE title_de = ?",
(description, title),
)
else:
descriptions.append("no description")
cur.execute(
" UPDATE events SET description_de = ? WHERE title_de = ?",
("no description", title),
)
# add list of sources to list
if "<h4>Links</h4>" in str(block):
a_href = []
for link in block.find_all("a"):
if "#?tag" in str(link) or "#20" in str(link):
continue
a_href.append(link.get("href"))
sources.append(a_href[1:-1])
else:
sources.append([])
# add list of tags to list
if "<h4>Links</h4>" in str(block):
a_href = []
for tag in block.find_all("a"):
if not "#?tag" in str(tag):
continue
a_href.append(tag.get_text())
t = tag.get_text()
cur.execute(""" INSERT OR IGNORE INTO tags (name) VALUES (?) """, (t,))
cur.execute(" SELECT id FROM events WHERE title_de = ? LIMIT 1", (title,))
e_id = cur.fetchone()[0]
cur.execute(" SELECT id FROM tags WHERE name = ? LIMIT 1", (t,))
t_id = cur.fetchone()[0]
cur.execute(
""" INSERT OR IGNORE INTO event_tags (event_id, tag_id) VALUES (?, ?)""",
(e_id, t_id),
)
tags.append(a_href)
else:
tags.append([])
conn.commit()Three Kinds of Keys
-
A logical key is a key that the “real world” might use to look up a row. In our example data model, the name field is a logical key. It is the screen name for the user and we indeed look up a user’s row several times in the program using the name field. You will often find that it makes sense to add a UNIQUE constraint to a logical key. Since the logical key is how we look up a row from the outside world, it makes little sense to allow multiple rows with the same value in the table.
-
A primary key is usually a number that is assigned automatically by the database. It generally has no meaning outside the program and is only used to link rows from different tables together. When we want to look up a row in a table, usually searching for the row using the primary key is the fastest way to find the row. Since primary keys are integer numbers, they take up very little storage and can be compared or sorted very quickly. In our data model, the id field is an example of a primary key.
-
A foreign key is usually a number that points to the primary key of an associated row in a different table. An example of a foreign key in our data model is the from_id.
Using JOIN top Retrieve Data
To query our event database, we have to use JOIN clauses to reconnect our
disparate tables on a certain field. For example, in order to retrieve all
events in one category the following query does the job:
SELECT * FROM events
JOIN categories c on events.category_id = c.id
WHERE c.name = 'committee hearing'we have to use a double JOIN statement to retrieve events with a particular
tag, such as “NSA”.
SELECT * FROM events
JOIN event_tags et on events.id = et.event_id
JOIN tags t on et.tag_id = t.id WHERE t.name = 'NSA'Summary
This chapter has covered a lot of ground to give you an overview of the basics of using a database in Python. It is more complicated to write the code to use a database to store data than Python dictionaries or flat files so there is little reason to use a database unless your application truly needs the capabilities of a database. The situations where a database can be quite useful are: (1) when your application needs to make many small random updates within a large data set, (2) when your data is so large it cannot fit in a dictionary and you need to look up information repeatedly, or (3) when you have a long-running process that you want to be able to stop and restart and retain the data from one run to the next.
You can build a simple database with a single table to suit many application needs, but most problems will require several tables and links/relationships between rows in different tables. When you start making links between tables, it is important to do some thoughtful design and follow the rules of database normalization to make the best use of the database’s capabilities. Since the primary motivation for using a database is that you have a large amount of data to deal with, it is important to model your data efficiently so your programs run as fast as possible.